There is no one fixed solution for choosing a database. This blog covers the 4 types of NoSQL databases which are Key-value pairs, Columnar, Document, and Graph. Along with some examples of where to use each type of database.
What do you mean by a database?
A database is any type of mechanism used for storing, managing, and retrieving information. It is a repository or collection of data.
A database’s implementation and how data is structured will determine how well an application will perform as it scales. There are two primary types of databases, relational and non-relational.
- Relational databases(SQL databases): they use the Structured Query Language to manage information storage and retrieval.
- Non-relational databases(NoSQL databases): NoSQL databases are often distributed databases where data is stored on multiple computers or nodes.
Each database type is optimized to support a specific type of workload. Matching an application with the appropriate database type is essential for highly performant and cost-efficient operation.
Why to use Non relational data bases?
While relational databases are highly-structured repositories of information, non-relational databases do not use a fixed table structure. They are schema-less.
Since it doesn’t use a predefined schema that is enforced by a database engine, a non-relational database can use structured, semi-structured, and unstructured data without difficulty.

NoSQL databases are popular with developers because they do not require an upfront schema design; they are able to build code without waiting for a database to be designed and built.
How to choose between Consistency, Availability and Partition tolerance(CAP theorem)?
Most NoSQL databases relax ACID constraints found in relational databases. NoSQL solutions were developed around the purpose of providing high availability and scalability in a distributed environment. To do this, either consistency or durability has to be sacrificed according to CAP theorem.

By relaxing consistency, distributed systems can be highly available and durable. It’s possible for data to be inconsistent; a query might return old or stale data. You might hear this phenomenon described as being eventually consistent. Over time, data that is spread across storage nodes will replicate and become consistent. What makes this behavior acceptable is that developers can anticipate this eventual consistency and allow for it.
Scaling a NoSQL database is easier and less expensive than scaling a relational database because the scaling is horizontal instead of vertical. NoSQL databases generally trade consistency for performance and scalability.
NoSQL databases are often run in clusters of computing nodes. Data is partitioned across multiple computers so that each computer can perform a specific task independently of the others. Each node performs its task without having to share CPU, memory, or storage with other nodes. This is known as a shared-nothing architecture.
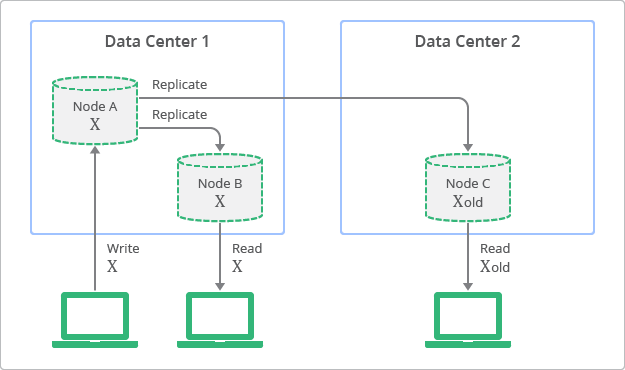
Different types of NoSQL databases
There are a variety of No SQL data base applications ranging from key value to graph based data bases. A single database can’t be efficient in all the cases and we have to choose a data base efficient for our use case,
1.Key value data store:
Saves data as a group of key value pairs, which are made up of two data items that are linked. The link between the items is a “key” which acts as an identifier for an item within the data and the “value”that is the data that has been identified.

Key value systems treat the data as a single opaque collection which may have different fields for every record. Hence, they generally use much less memory while saving and storing the same amount of data, which in turn, increases the performance for certain workloads. In each key value pair,
- The key is represented by an arbitrary string
- The value can be any kind of data like an image, file, text or document
The value is stored as a blob requiring no upfront data modeling. This offers considerable flexibility and more closely follows modern concepts like object-oriented programming. As optional values are not represented by placeholders, it leads to less memory used to store. The storage of the value as a blob removes the need to index the data to improve performance. You cannot filter or control whats returned from a request based on the value because the value is opaque.
When to use key value stores ?
Key-value stores handle size well and are good at processing a constant stream of read/write operations with low latency making them perfect for,
- Session management at high scale
- User preference and profile stores
- Can effectively work as a cache for heavily accessed but rarely updated data
Advantages of Key value stores,
- For most key value stores, the secret to its speed lies in its simplicity. The path to retrieve data is a direct request to the object in memory or on disk.
- The relationship between data does not have to be calculated by a query language, there is no optimization performed.
- They can exist on distributed systems and don’t need to worry about where to store indexes, how much data exists on each system or the speed of a network with a distributed system they just work.
Disadvantages of Key value stores,
- No complex query filters
- All joins must be done in code
- No foreign key constraints
- No trigger
Some notable examples of Key value data stores are Amazon Dynamo DB, Redis and Aerospike. For more information on key value stores, go to my blog focusing more on Key value stores and it’s use cases as well architecture.
2.Columnar data store:
While a relational database is optimized for storing rows of data, typically for transactional applications, a columnar database is optimized for fast retrieval of columns of data, typically in analytical applications.
Column-oriented storage for database tables is an important factor in analytic query performance because it drastically reduces the overall disk I/O requirements and reduces the amount of data you need to load from the disk.
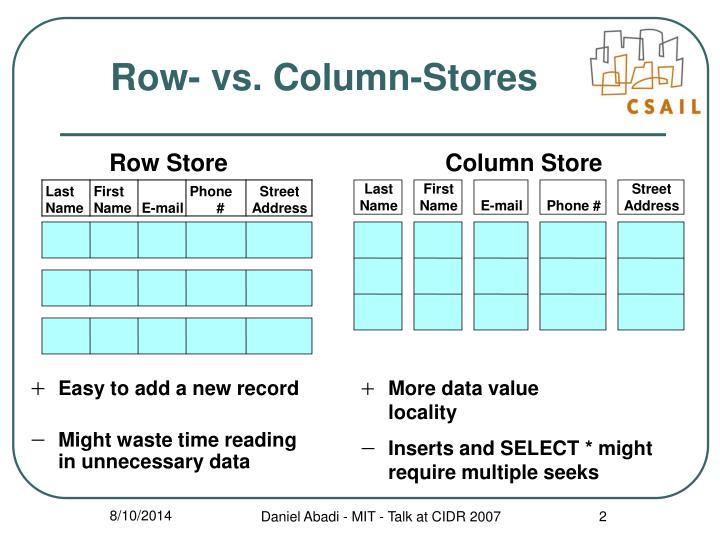
Like other NoSQL databases, column-oriented databases are designed to scale “out” using distributed clusters of low-cost hardware to increase throughput, making them ideal for data warehousing and Big Data processing.
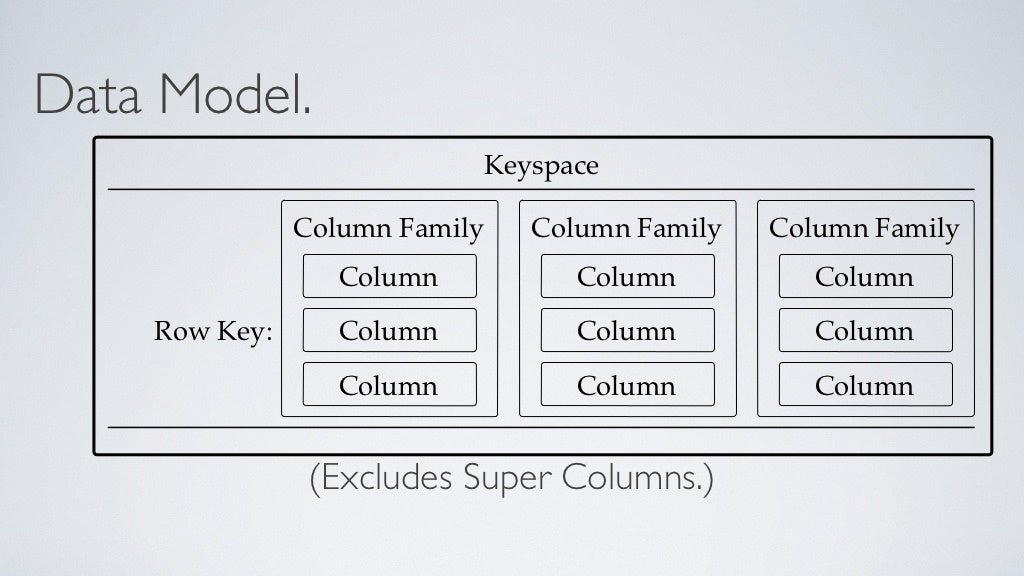
Terminologies used in a columnar data store?
- Keyspace defines how a dataset is replicated. Kind of like a schema in the relational model and it contains all the column families.
- The table defines the typed schema for a collection of partitions.
- Tables contain partitions, which contain partitions, which contain columns.
- Partition defines the mandatory part of the primary key all rows. All performant queries supply the partition key in the query.
- A column family consists of multiple rows.
- Each row can contain a different number of columns than the other rows. And the columns don’t have to match the columns in the other rows.
- Each column is contained to its row. It doesn’t span all rows like in a relational database. Each column contains a name/value pair, along with a timestamp. Note that this example uses Unix/Epoch time for the timestamp.
Most column stores are traditionally loaded in batches that can optimize the column store process and the data is pretty much always compressed on disk to overcome the increased amount of data to be stored. Hence we mostly use Column data stores for data warehousing and data processing, which is evident in services such as Amazon Redshift.
Advantages of column data stores
- Column stores are very efficient at data compression and/or partitioning.
- Due to their structure, columnar databases perform particularly well with aggregation queries.
- Columnar databases are very scalable. As they are well suited to massively parallel processing.
- Columnar stores can be loaded extremely fast.
Disadvantages of column data store
- Updates can be inefficient. The fact that columnar families group attributes, as opposed to rows of tuples, works against it.
- If multiple attributes are touched by a join or query, this may also lead to column storage experiencing slower performance.
- It’s also slower when deleting rows from columnar systems, as a record needs to be deleted from each of the record files.
Some notable examples of Columnar value data stores are AWS Redshift, Google BigTable, Apache Casandra and Hadoop Base. For more information on columnar value stores, go to my blog focusing more on column value stores and it’s use cases as well architecture.
- https://programmerprodigy.code.blog/2021/06/28/introduction-to-columnar-value-data-store-along-with-use-cases/
- https://programmerprodigy.code.blog/2021/06/28/introduction-to-hadoophdfs-and-hbase/
3.Document Data store:
A document database is a type of non relational database that is designed to store and query data as JSON-like documents. Document databases make it easier for developers to store and query data in a database by using the same document-model format they use in their application code.
They are flexible, semi structured, and hierarchical nature of documents and document databases allows them to evolve with applications’ needs. A document database is, at its core, a key/value store with one major exception. Instead of just storing any blob in it, a document db requires that the data will be store in a format that the database can understand.

The metadata also allows the document format to be changed at any time without affecting the existing records. Fields can be added at any time, anywhere, with no need to change the physical storage.
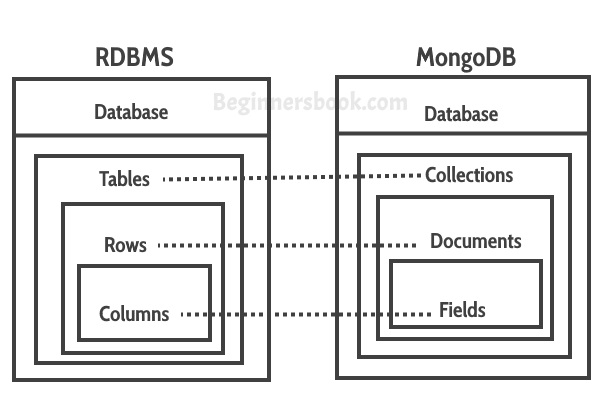
Terminologies in document data store?
- A table is called a collection
- A row is called a document
- A column in called a field
The document model works well with use cases such as catalogs, user profiles, and content management systems where each document is unique and evolves over time.
Advantages of Document Data stores:
- Instead of grabbing the data from the hard disk during a query, it grabs the data from the RAM and query returns come back much quicker.
- Very dynamic schematics architecture for unstructured data and storage options
- Sharding for horizontal scalability
- Replication is managed internally, so chances of accidental loss of data is negligible.
Disadvantages of Document data stores:
- No support for transactions, which could lead to data corruption
- Pulling data from several collections requires a number of queries, which will inevitably lead to messy code and long turn-around times.
- The relationships are not typically well-defined and the resulting duplicate data sets can be hard to handle.
- No views, triggers, scripts or stored procedure.
Some notable examples of Document value data stores are AWS DocumentDB, Mongo DB and Couch DB. For more information on document value stores, go to my blog focusing more on document value stores and it’s use cases as well architecture.
4.Graph data store:
A graph database is a database designed to treat the relationships between data as equally important to the data itself. Accessing nodes and relationships in a native graph database is an efficient, constant-time operation and allows you to quickly traverse millions of connections per second per core.
Independent of the total size of your dataset, graph databases excel at managing highly-connected data and complex queries.

Data Modeling ?
Nodes are the entities in the graph. They can hold any number of attributes called properties. Nodes can be tagged with labels, representing their different roles in your domain. Node labels may also serve to attach metadata to certain nodes.
Relationships provide directed, named, semantically-relevant connections between two node entities. A relationship always has a direction, a type, a start node, and an end node. Like nodes, relationships can also have properties.
Developing with graph technology aligns perfectly with today’s agile, test-driven development practices, allowing your graph-database-backed application to evolve with your changing business requirements. As, you are the one dictating changes and taking charge.
Managing data as graphs is a particularly good fit when the use case involves modifying schemas and accommodating new features, data points, or sources.
Due to the efficient way relationships are stored, two nodes can share any number or type of relationships without sacrificing performance. Although they are stored in a specific direction, relationships can always be navigated efficiently in either direction.

Graph databases are most useful when handling data containing relationships that have important associated context. Some examples are,
- Knowledge graphs.
- Recommendation engines.
- Social networking applications such as LinkedIn and Facebook
- Supply chain management.
- Chat bots
Advantages of Graph data stores,
- More descriptive queries
- Greater flexibility in adapting your model
- Greater performance when traversing data relationships
Disadvantages of Graph data stores,
- Difficult to scale, i.e. Sharding
- No standard language.
Some notable examples of Document value data stores are AWS Neptune and Neo 4J. For more information on columnar value stores, go to my blog focusing more on document value stores and it’s use cases as well architecture.

{kind=link}
This so was helpful mate keep up the great work
LikeLiked by 1 person
Wow, amazing weblog structure! How long have you ever been running a blog for? you make blogging glance easy. The full look of your site is magnificent, let alone the content material!
LikeLike