Hadoop uses distributed file system for storing big data, and Map Reduce to process. Hadoop excels in storing and processing of huge data of various formats such as arbitrary, semi -, or even unstructured. This blog covers HDFS, architecture of HDFS, HBase and architecture of HBase.
1.Hadoop Distributed File System (HDFS):
HDFS is a distributed file system that handles large data sets running on commodity hardware. It is used to scale a single Apache Hadoop cluster to hundreds of nodes. HDFS is one of the major components of Apache Hadoop.
It is mainly used for Streaming data access. Applications which need streaming access to data. Batch processing is preferred rather than interactive user access.
A HDFS instance may consist of thousands of server machine, each storing part of the file system’s data. Since we have huge number of components and that each component has non trivial probability of failure means that there is always some component that is non functional. Detection of faults and quick, automatic recovery from them is a core architectural goal of HDFS.
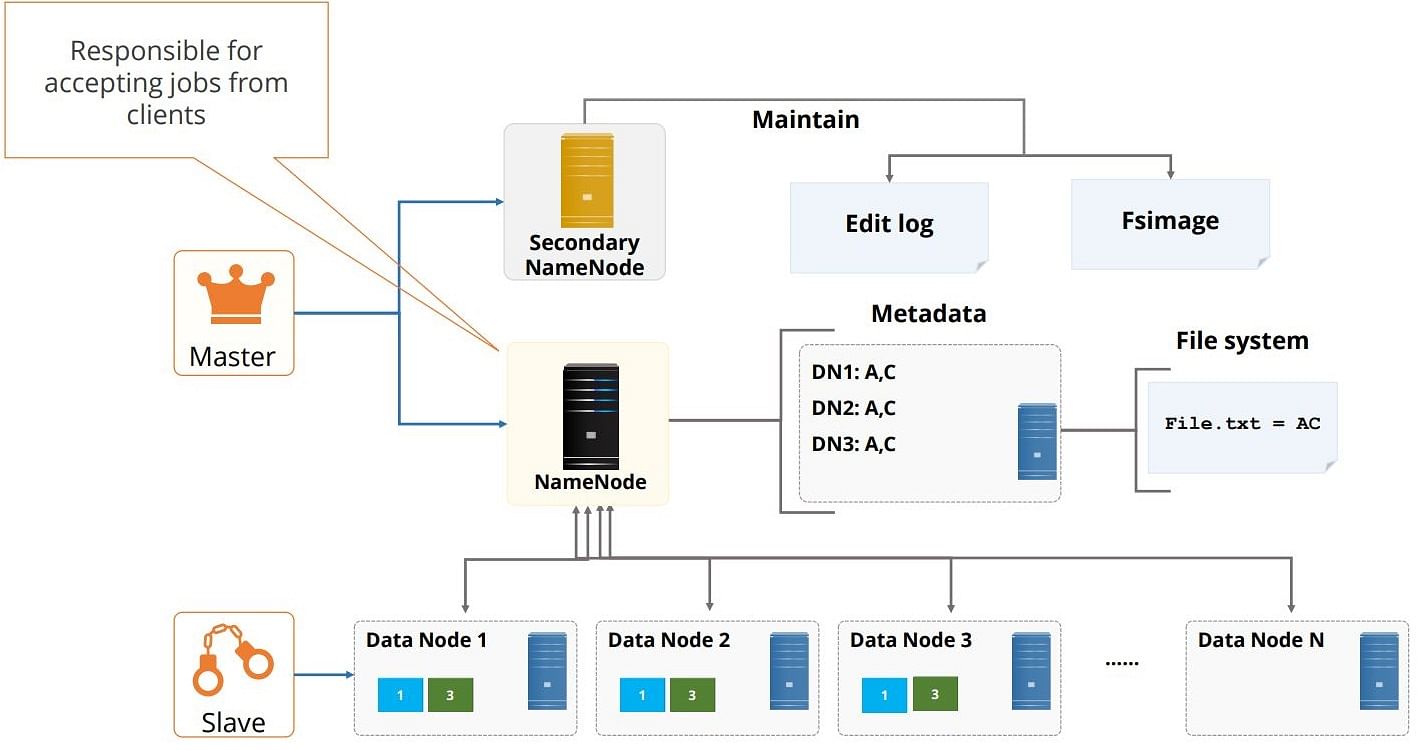
Architecture of HDFS?
HDFS cluster consists of a single Name node, a master server that manages the file system namespace and regulates access to files by clients.
There are a number of Data Nodes usually one per node in a cluster. The Data Nodes manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and that allows user data to be stored in files.
A file is split into one or more blocks and a set of blocks are stored in Data Nodes. A hierarchical file system with directories and files.
- Data nodes serves read, write requests, performs block creation, deletion, and replication upon instruction from Name node.
- Name node maintains the files system. Any meta information changes to the file system recorded by the Name node.
An application can specify the number of replicas of the file needed(Replication factor of the file), which is stored in the Name node.
Data Replication and Replica Placement in HDFS?
HDFS is designed to store very large files across machines in a large cluster, where
- Each file is a sequence of blocks.
- All blocks in the file except the last are of the same size.
- Blocks are replicated for fault tolerance.
- Block size and replicas are configurable per file.
- The Name node receives a Heartbeat and a Block Report from each Data node in the cluster.
- Block Report contains all the blocks on a Data node.
The placement of the replicas is critical to HDFS reliability and performance. Optimizing replica placement distinguishes HDFS from other distributed file systems.
Many racks, communication between racks are through switches. Network bandwidth between machines on the same rack is greater than those in different racks. Name node determines the rack id for each Data Node. Replicas are typically placed on unique racks.
HDFS tries to minimize bandwidth consumption and latency. If there is a replica on the Reader node then that is preferred, and the replica in the local data center is preferred over the remote one.

On startup Name mode enters Safe mode. Replication of data blocks do not occur in Safe mode.
Metadata in File system?
A.Name Node:
- The HDFS namespace is stored by Name node.
- Name node uses a transaction log called the Edit Log to record every change that occurs to the file system meta data.
- The entire filesystem namespace including mapping of blocks to files and file system properties is stored in a file FsImage. Stored in Name node’s local file system.
- Name node keeps image of entire file system namespace and file Block map in memory
When the name node starts up it gets the FsImage and Edit log from its local file system, updates FsImage with Edit log information and then stores a copy of the FsImage on the filesystem as a checkpoint. So, periodic check pointing is done.
B.Data Node:
- A data node stores data in files in it’s local file system. Data node has no knowledge about HDFS filesystem.
- It stores each block of HDFS data in a separate file. Data node does not create all files in the same directory.
- When the filesystem starts up it generates a list of all HDFS blocks and sends this report to the Name node, which is called a Block Report.
Cluster re-balancing and data integrity?
HDFS architecture is compatible with data re-balancing schemes. A scheme might move data from on Data node to another if free space on a data node falls below a certain threshold. In the event of a sudden high demand for a particular file, a scheme might dynamically create additional replicas and re-balance other data in the cluster.
For maintaining the data integrity,
- A HDFS client creates the checksum of every block of its file and stores it in hidden files in the HDFS namespace.
- FsImage and Edit Log are central data structures of HDFS. A corruption of these files can cause a HDFS instance to be non functional.
- For this reason, a Name node can be configured to martian multiple copies of the FsImage and Edit Log.
- Multiple copies of the FsImage and Edit Log files are updated synchronously. Meta-data is not data intensive
The Name node could be single point failure: automatic fail over is not supported.
Data Organization?
- A client request to create a file does not reach Name node immediately and the HDFS client caches the data into a temporary file.
- When the data reached a HDFS block size the client contacts the Name node.
- Name node inserts the filename into its hierarchy and allocates a data block for it
- The name node responds to the client with the identity of the data node and the destination of the replicas for the block
- Then the client flushes it from its local memory and sends a message that the file is closed.
- Name node proceeds to commit the file for creation operation into the persistent store.
- If the name node dies before file is closed, the file is lost
- This client side caching is required to avoid network congestion.
- When the client receives response from Name node, it flushes its block in small pieces to the first replica, that in turn copies to the next replica and so on
Thus data is pipe lined from data node to the next.

Space Reclamation?
When a file is deleted by a client, HDFS renames file to a file in the /trash directory for a configurable amount of time.
A client can request for an un-delete in this allowed time. After the specified time the file is deleted and the space is reclaimed.
When the replication factor is reduced, the Name node selects excess replicas that can be deleted. Next heartbeat transfers this information to the data node that clears the blocks for use.
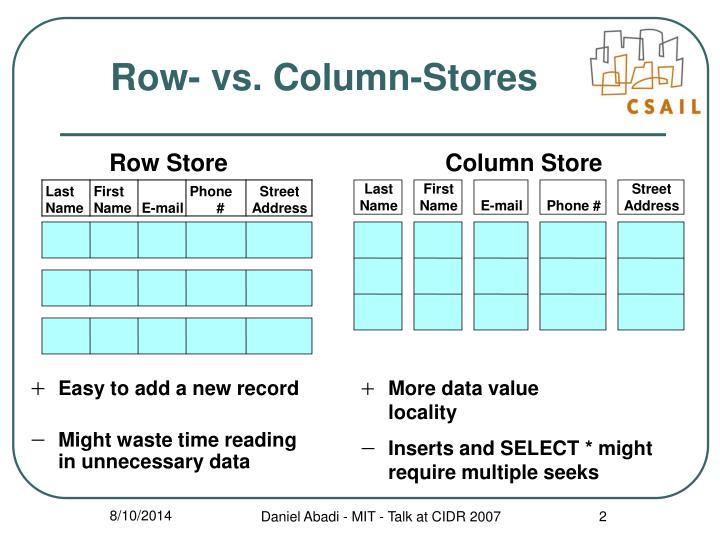
What do you mean by Column oriented storage?
Column-oriented storage for database tables is an important factor in analytic query performance because it drastically reduces the overall disk I/O requirements and reduces the amount of data you need to load from the disk.
Column Data Stores is a database in which data is stored in cells grouped in columns of data rather than as rows of data. Columns are logically grouped into column families.
Like other NoSQL databases, column-oriented databases are designed to scale “out” using distributed clusters of low-cost hardware to increase throughput, making them ideal for data warehousing and Big Data processing.
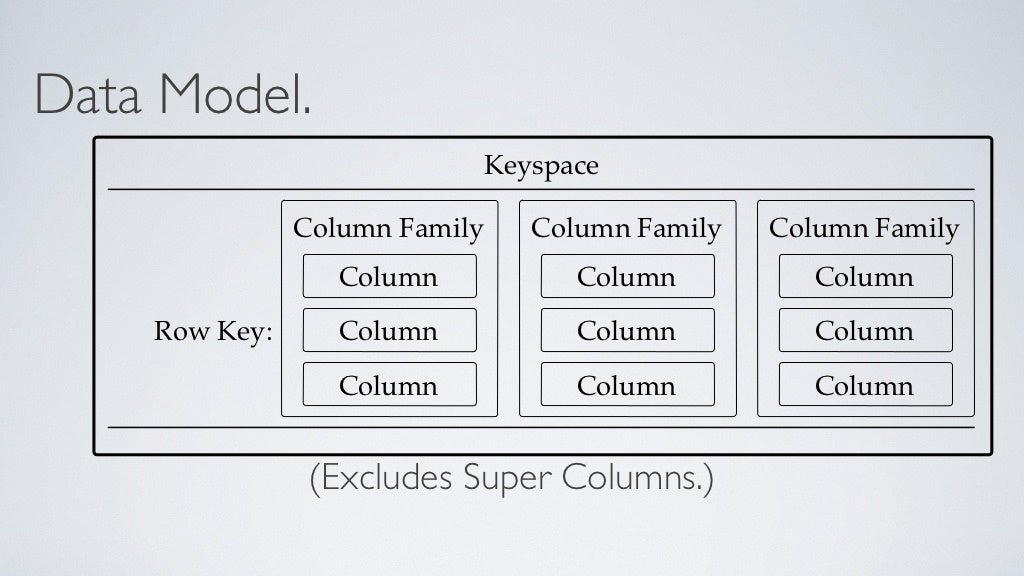
Terminologies used in a columnar data store?
- Keyspace defines how a dataset is replicated. Kind of like a schema in the relational model and it contains all the column families.
- The table defines the typed schema for a collection of partitions.
- Tables contain partitions, which contain partitions, which contain columns.
- Partition defines the mandatory part of the primary key all rows. All performant queries supply the partition key in the query.
- A column family consists of multiple rows.
- Each row can contain a different number of columns than the other rows. And the columns don’t have to match the columns in the other rows.
- Each column is contained to its row. It doesn’t span all rows like in a relational database. Each column contains a name/value pair, along with a timestamp. Note that this example uses Unix/Epoch time for the timestamp.
Most column stores are traditionally loaded in batches that can optimize the column store process and the data is pretty much always compressed on disk to overcome the increased amount of data to be stored. Hence we mostly use Column data stores for data warehousing and data processing.
2.HBase
It is a distributed column oriented database built on top of the Hadoop file system, which is horizontally scalable.
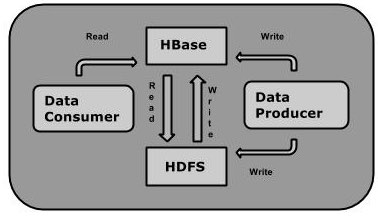
HBase is a data model similar to Google’s big table designed to provide quick random access to huge amounts of structured data.
You can store the data in HDFS either directly or through Hbase. Data consumer reads the data in HDFS randomly using HBase. Hbase sits on top of the Hadoop file system and provides read and write access.
Storage mechanism Mechanism in HBase?
HBase is a column-oriented database and the tables in it are sorted by row. The table schema defines only column families, which are the key value pairs. A table have multiple column families and each column family can have number of columns. Subsequent column values are stored contiguously on the disk. Each cell value of the table has a timestamp.
- Table is a collection of rows
- Row is a collection of column families
- Column family is a collection of columns
- Column is a collection of key value pairs.
In HBase, tables are split into regions and are served by the region servers. Regions are vertically divided by column families into “Stores”. Stores are saved as files in HDFS. Shown below is the architecture of HBase.
Architecture in HBase?
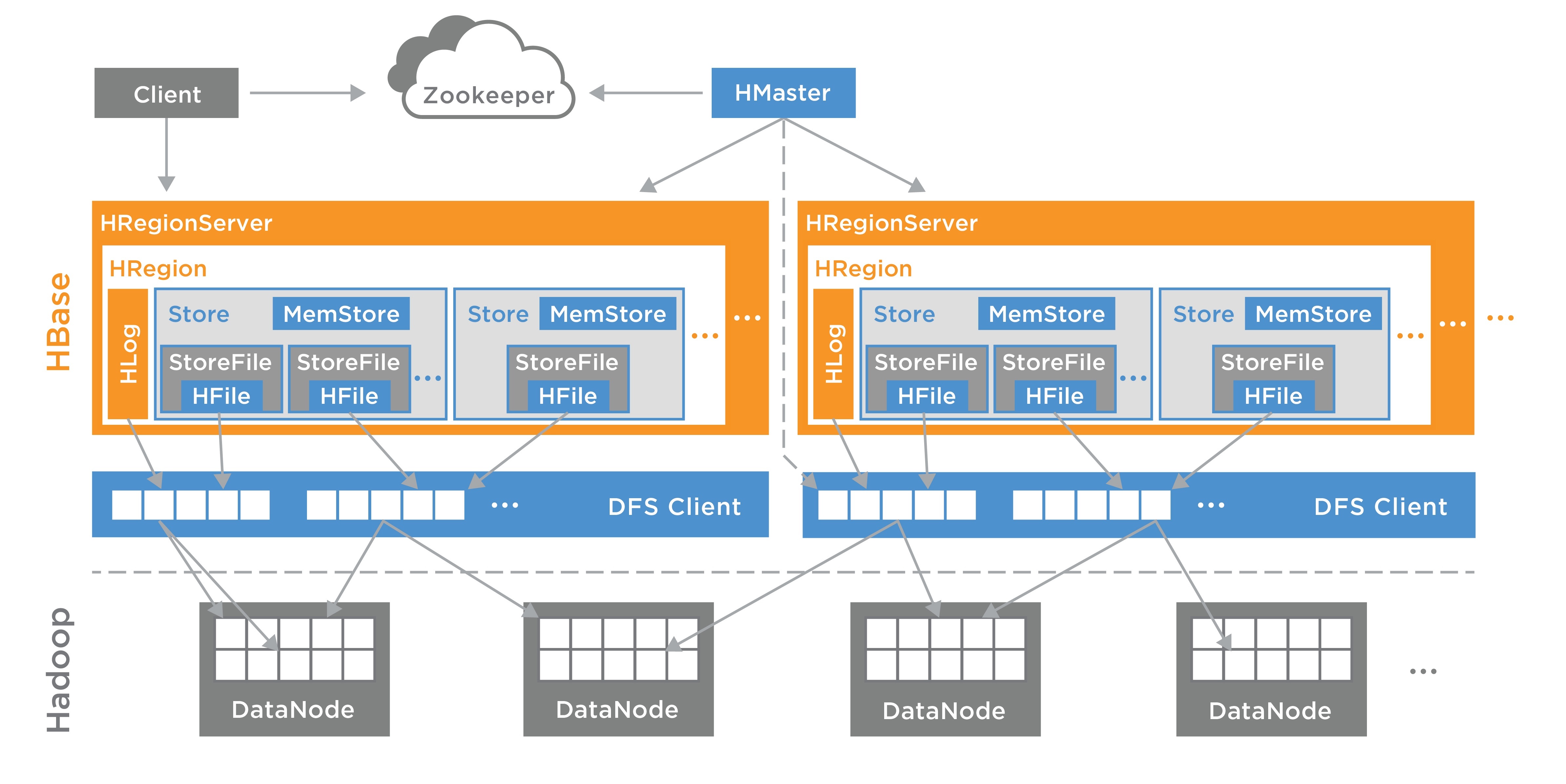
HBase has three major components: the client library, a master server, and region servers. Region servers can be added or removed as per requirement.
A.Master Server:
- Assigns regions to the region servers and takes the help of Apache Zookeeper for this track.
- Handles Load balancing of the regions across regions servers. It unloads the busy servers and shifts the regions to less occupied servers.
- Maintains the state of the cluster by negotiating the load balancing
- Responsible for schema changes and other metadata operations such as creation of tables nad column families.
B. Regions Server:
Regions are nothing but tables that are split up and spread across the region servers. The region servers have regions that,
- Communicate with the client and handle data related operations
- handle read and write requests for all regions under it.
- Decide the size of the region by following the region size thresholds.
C.Store:
The store contains memory store and HFiles.
- Memstore is just like cache memory.
- Later that data is transferred and saved in Hfiles as blocks and the memstore is flushed.
D.Zookeeper
Zookeeper is an open source project that provides services like maintaining configuration information, naming, providing distributed synchronization.
- Zookeeper has ephemeral nodes representing different region servers. Master servers use these nodes to discover available servers
- In addition to availability, the nodes are also used to track server failures or network partitions
- Clients communicate with region servers via zookeeper.
- HBase itself can take care of zookeeper.

6 thoughts on “Introduction to Hadoop(HDFS and HBase)”