This blog focuses primarily on graph value data stores, its example along with their architecture and features. Example used is Neo 4J.
What do you mean by a database?
A database is any type of mechanism used for storing, managing, and retrieving information. It is a repository or collection of data.
A database’s implementation and how data is structured will determine how well an application will perform as it scales. There are two primary types of databases, relational and non-relational.
- Relational databases(SQL databases): they use the Structured Query Language to manage information storage and retrieval.
- Non-relational databases(NoSQL databases): NoSQL databases are often distributed databases where data is stored on multiple computers or nodes.
Each database type is optimized to support a specific type of workload. Matching an application with the appropriate database type is essential for highly performant and cost-efficient operation.
Why to use Non relational data bases?
While relational databases are highly-structured repositories of information, non-relational databases do not use a fixed table structure. They are schema-less.
Since it doesn’t use a predefined schema that is enforced by a database engine, a non-relational database can use structured, semi-structured, and unstructured data without difficulty.

NoSQL databases are popular with developers because they do not require an upfront schema design; they are able to build code without waiting for a database to be designed and built.
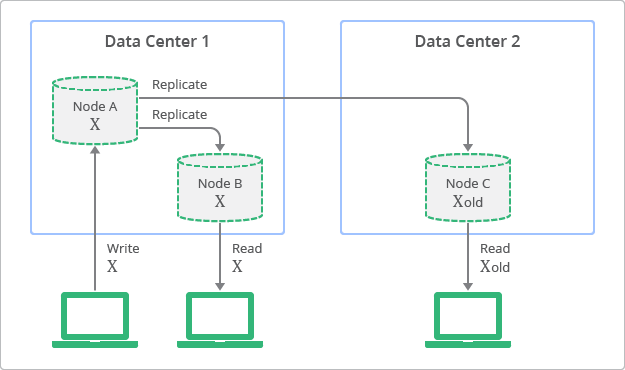
By relaxing consistency, distributed systems can be highly available and durable. It’s possible for data to be inconsistent; a query might return old or stale data. You might hear this phenomenon described as being eventually consistent. Over time, data that is spread across storage nodes will replicate and become consistent. What makes this behavior acceptable is that developers can anticipate this eventual consistency and allow for it.
Scaling a NoSQL database is easier and less expensive than scaling a relational database because the scaling is horizontal instead of vertical. NoSQL databases generally trade consistency for performance and scalability.
NoSQL databases are often run in clusters of computing nodes. Data is partitioned across multiple computers so that each computer can perform a specific task independently of the others. Each node performs its task without having to share CPU, memory, or storage with other nodes. This is known as a shared-nothing architecture.
Graph data store
A graph database is a database designed to treat the relationships between data as equally important to the data itself. It is intended to hold data without constricting it to a pre-defined model.
Accessing nodes and relationships in a native graph database is an efficient, constant-time operation and allows you to quickly traverse millions of connections per second per core.
Independent of the total size of your dataset, graph databases excel at managing highly-connected data and complex queries. With only a pattern and a set of starting points, graph databases explore the neighboring data around those initial starting points, collecting and aggregating information from millions of nodes and relationships, and leaving any data outside the search perimeter untouched.

Data Modeling ?
Nodes are the entities in the graph. They can hold any number of attributes called properties. Nodes can be tagged with labels, representing their different roles in your domain. Node labels may also serve to attach metadata to certain nodes.
Relationships provide directed, named, semantically-relevant connections between two node entities. A relationship always has a direction, a type, a start node, and an end node. Like nodes, relationships can also have properties.
Developing with graph technology aligns perfectly with today’s agile, test-driven development practices, allowing your graph-database-backed application to evolve with your changing business requirements. As, you are the one dictating changes and taking charge.
Managing data as graphs is a particularly good fit when the use case involves modifying schemas and accommodating new features, data points, or sources.
Due to the efficient way relationships are stored, two nodes can share any number or type of relationships without sacrificing performance. Although they are stored in a specific direction, relationships can always be navigated efficiently in either direction.

Graph databases are most useful when handling data containing relationships that have important associated context. Some examples are,
- Knowledge graphs.
- Recommendation engines.
- Social networking applications such as LinkedIn and Facebook
- Supply chain management.
- Chat bots
Advantages of Graph data stores,
- More descriptive queries
- Greater flexibility in adapting your model
- Greater performance when traversing data relationships
Disadvantages of Graph data stores,
- Difficult to scale, i.e. Sharding
- No standard language.
AI and machine learning applications can understand and analyze the relationships, between entities within the dataset or the content set in the graph form. Graph databases also run more efficiently across highly-connected datasets.
Examples for Graph data store
A.Neo 4j
Neo4j is an open-source, NoSQL, native graph database that provides an ACID-compliant transactional backend for your applications.
Neo4j offers a graph database that helps organizations make sense of their data by revealing how people, processes and systems are related. Neo4j natively stores interconnected data so it’s easier to decipher data.
Neo4j is referred to as a native graph database because it efficiently implements the property graph model down to the storage level. This means that the data is stored exactly as you whiteboard it, and the database uses pointers to navigate and traverse the graph. Some of the following particular features make Neo4j very popular among developers, architects, and DBAs:
- Cypher, a declarative query language similar to SQL, but optimized for graphs. Now used by other databases like SAP HANA Graph and Redis graph via the openCypher project.
- Constant time traversals in big graphs for both depth and breadth due to efficient representation of nodes and relationships. Enables scale-up to billions of nodes on moderate hardware.
- Flexible property graph schema that can adapt over time, making it possible to materialize and add new relationships later to shortcut and speed up the domain data when the business needs change.
- Drivers for popular programming languages, including Java, JavaScript, .NET, Python, and many more.
Architecture?
Unless you’re building a desktop app or you’re building a small, lightly trafficked, non-critical web app, you’re going to want to be using Neo4j in its clustered form.
We can cluster Neo4j instances for high read throughput and high availability, and this is a feature of the enterprise version of the product. Today, Neo4j employs a traditional master/slave architecture.

The other instances in the cluster act as slaves, and they’re polling the master at frequent intervals in order to pull transactions across.
If you write directly to the master, then, when the control returns to the client, you’re guaranteed your data has been made durable on disk, and the master is immediately consistent with respect to that client. The overall system, however, is eventually consistent

{kind=link}
{kind=link}
One thought on “Introduction to Graph value data store along with a use case”