This blog focuses primarily on columnar value data stores, its example along with their architecture and features. Examples are Apache Casandra and Google Big Table.
What do you mean by a database?
A database is any type of mechanism used for storing, managing, and retrieving information. It is a repository or collection of data.
A database’s implementation and how data is structured will determine how well an application will perform as it scales. There are two primary types of databases, relational and non-relational.
- Relational databases(SQL databases): they use the Structured Query Language to manage information storage and retrieval.
- Non-relational databases(NoSQL databases): NoSQL databases are often distributed databases where data is stored on multiple computers or nodes.
Each database type is optimized to support a specific type of workload. Matching an application with the appropriate database type is essential for highly performant and cost-efficient operation.
Why to use Non relational data bases?
While relational databases are highly-structured repositories of information, non-relational databases do not use a fixed table structure. They are schema-less.
Since it doesn’t use a predefined schema that is enforced by a database engine, a non-relational database can use structured, semi-structured, and unstructured data without difficulty.

NoSQL databases are popular with developers because they do not require an upfront schema design; they are able to build code without waiting for a database to be designed and built.
By relaxing consistency, distributed systems can be highly available and durable. It’s possible for data to be inconsistent; a query might return old or stale data. You might hear this phenomenon described as being eventually consistent. Over time, data that is spread across storage nodes will replicate and become consistent. What makes this behavior acceptable is that developers can anticipate this eventual consistency and allow for it.
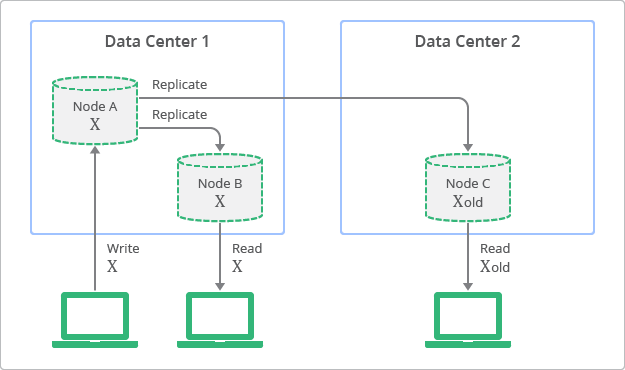
Scaling a NoSQL database is easier and less expensive than scaling a relational database because the scaling is horizontal instead of vertical. NoSQL databases generally trade consistency for performance and scalability.
NoSQL databases are often run in clusters of computing nodes. Data is partitioned across multiple computers so that each computer can perform a specific task independently of the others. Each node performs its task without having to share CPU, memory, or storage with other nodes. This is known as a shared-nothing architecture.
columnar data store:
While a relational database is optimized for storing rows of data, typically for transactional applications, a columnar database is optimized for fast retrieval of columns of data, typically in analytical applications.
Column-oriented storage for database tables is an important factor in analytic query performance because it drastically reduces the overall disk I/O requirements and reduces the amount of data you need to load from the disk.
Column Data Stores is a database in which data is stored in cells grouped in columns of data rather than as rows of data. Columns are logically grouped into column families.
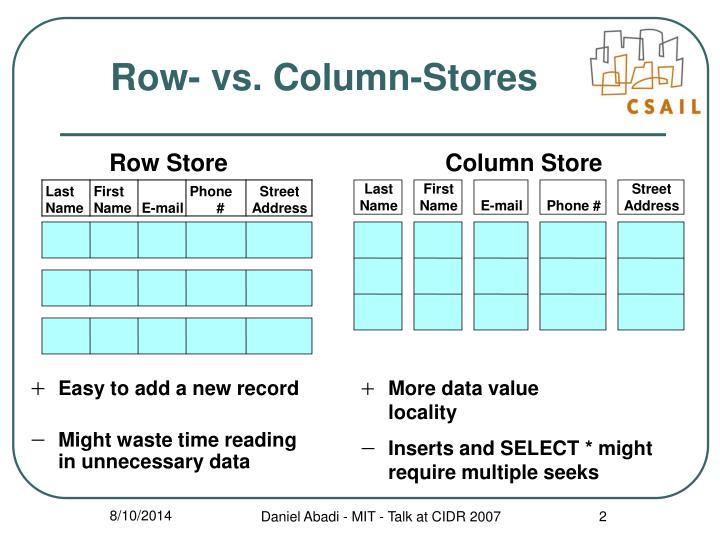
Like other NoSQL databases, column-oriented databases are designed to scale “out” using distributed clusters of low-cost hardware to increase throughput, making them ideal for data warehousing and Big Data processing.
Terminologies used in a columnar data store?
- Keyspace defines how a dataset is replicated. Kind of like a schema in the relational model and it contains all the column families.
- The table defines the typed schema for a collection of partitions.
- Tables contain partitions, which contain partitions, which contain columns.
- Partition defines the mandatory part of the primary key all rows. All performant queries supply the partition key in the query.
- A column family consists of multiple rows.
- Each row can contain a different number of columns than the other rows. And the columns don’t have to match the columns in the other rows.
- Each column is contained to its row. It doesn’t span all rows like in a relational database. Each column contains a name/value pair, along with a timestamp. Note that this example uses Unix/Epoch time for the timestamp.
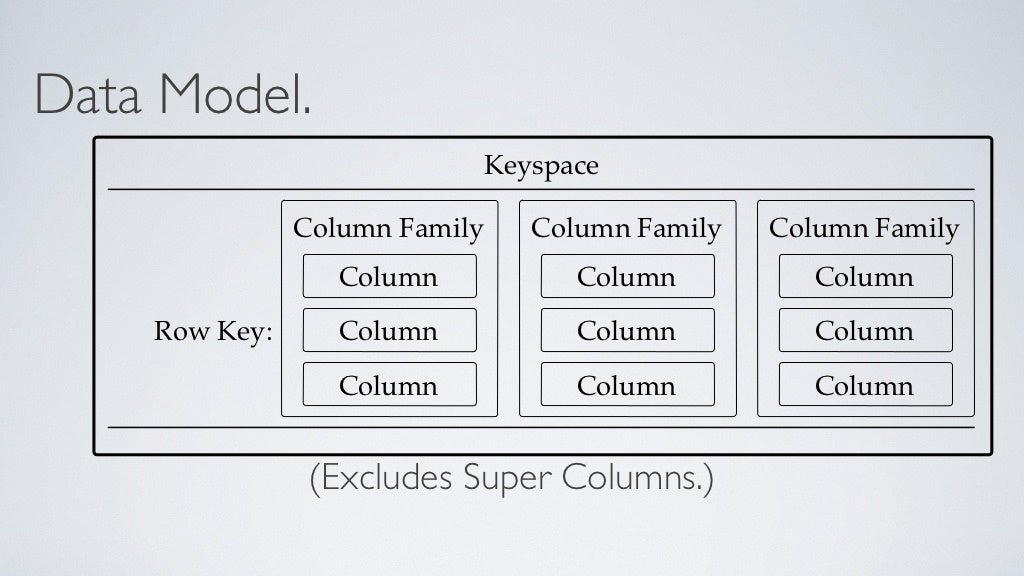
Most column stores are traditionally loaded in batches that can optimize the column store process and the data is pretty much always compressed on disk to overcome the increased amount of data to be stored. Hence we mostly use Column data stores for data warehousing and data processing, which is evident in services such as Amazon Redshift.
Advantages of column data stores
- Column stores are very efficient at data compression and/or partitioning.
- Due to their structure, columnar databases perform particularly well with aggregation queries.
- Columnar databases are very scalable. As they are well suited to massively parallel processing.
- Columnar stores can be loaded extremely fast.
Disadvantages of column data store
- Updates can be inefficient. The fact that columnar families group attributes, as opposed to rows of tuples, works against it.
- If multiple attributes are touched by a join or query, this may also lead to column storage experiencing slower performance.
- It’s also slower when deleting rows from columnar systems, as a record needs to be deleted from each of the record files.
Example of column data stores
A.Apache Cassandra
Apache Cassandra is an open source, distributed, NoSQL database. It presents a partitioned wide column storage model with eventually consistent semantics.
Since it is a distributed database, Cassandra can have multiple nodes. A node represents a single instance of Cassandra. These nodes communicate with one another through a protocol called gossip, which is a process of peer-to-peer communication.

Cassandra also has a master-less architecture, any node in the database can provide the exact same functionality as any other node. Contributing to Cassandra’s robustness and resilience. Multiple nodes can be organized logically into a cluster. Resulting in multiple data centers.
Cassandra provides the Cassandra Query Language (CQL), an SQL-like language, to create and update database schema and access data. CQL supports numerous advanced features over a partitioned dataset such as,
- Single partition lightweight transactions with atomic compare and set semantics.
- User-defined types, functions and aggregates.
- Collection types including sets, maps, and lists.
- Local secondary indices.
Cassandra explicitly chooses not to implement operations that require cross partition coordination as they are typically slow and hard to provide highly available global semantics. Cassandra does not support,
- Cross partition transactions.
- Distributed joins.
- Foreign keys or referential integrity.
For more information on Apache Cassandra,
- https://cassandra.apache.org/cassandra-basics/
- https://www.scylladb.com/resources/introduction-to-apache-cassandra/
B.Google Big table:
BigTable is a distributed storage system that is structured as a large table. it is a sparse, distributed, persistent multidimensional sorted map. The map is indexed by a row key, column key, and a timestamp; each value in the map is an uninterpreted array of bytes.

IT stores data in massively scalable tables, each of which is a sorted key/value map. The table is composed of rows, each of which typically describes a single entity, and columns, which contain individual values for each row. Each row/column intersection can contain multiple cells.
Each cell contains a unique timestamped version of the data for that row and column. Storing multiple cells in a column provides a record of how the stored data for that row and column has changed over time. Big table tables are sparse; if a column is not used in a particular row, it does not take up any space.
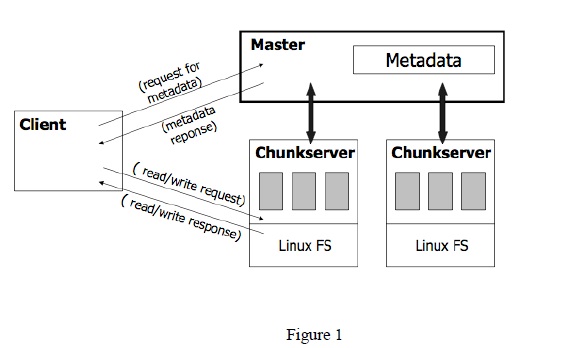
BigTable comprises a client library, a master server that coordinates activity, and many tablet servers. Tablet servers can be added or removed dynamically.
- The master assigns tablets to tablet servers and balances tablet server load. It is also responsible for garbage collection of files in Google File Storage and managing schema changes.
- Each tablet server manages a set of tablets, It handles read/write requests to the tablets it manages and splits tablets when a tablet gets too large.
- Each Tablet Server starts with a single tablet. When the size of this tablet becomes large it gets split into two tablets.
- The Tablet location information is stored using a B+ tree kind of hierarchy.
Client data does not move through the master; clients communicate directly with tablet servers for reads/writes.

The internal file format for storing data is Google’s Sorted Strings Table(SS Table). It provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range.
BigTable uses the Google File System (GFS) for storing both data files and logs. A cluster management system contains software for scheduling jobs, monitoring health, and dealing with failures.
Big table relies on a highly-available and persistent distributed lock service called Chubby. Centralized coordination service with locking semantics. The primary goal is to provide a reliable lock service. Chubby is NOT optimized for high performance, frequent locking scenarios.
Client caches tablet locations. In case if it does not know, it has to make three network round-trips in case the cache is empty and up to six round trips in case the cache is stale. Tablet locations are stored in memory, so no GFS accesses are required.
Google File System ?
- A lower layer (a set of chunk servers) stores the data in units called “chunks”.
- A master process maintains the metadata.
What is a chunk?
Stored on chunkserver as fileChunk handle used to reference chunk. Chunk replicated across multiple chunkservers
What is a master?
A single process running on a separate machine. Stores all metadata: File namespaceFile to chunk mappings, Chunk location information ,Access control information, Chunk version numbers , ….
Master and chunk server communicate regularly to obtain state. Master sends instructions to chunk server.
Serving Requests?
- Client retrieves metadata for operation from master.
- Read/Write data flows between client and chunk server.
- Single master is not bottleneck, because its involvement with read/write operations is minimized.
Master and Chunk servers are designed to restart and restore state in a few seconds. As well as Each chunk has an associated checksum.
Chunk Replication?
Across multiple machines, across multiple racks. Master Mechanisms:
- Log of all changes made to metadata.
- Periodic checkpoints of the log. Log and checkpoints replicated on multiple machines.
- Master state is replicated on multiple machines.“Shadow” masters for reading data if “real” master is down.
for more information on google big table,
Another example of columnar database is Hadoop, but to understand HBase you have to understand HDFS. It was a complete blog in itself,
https://programmerprodigy.code.blog/2021/06/28/introduction-to-hadoophdfs-and-hbase/

{kind=link}
{kind=link}
{kind=link}
One thought on “Introduction to columnar value data store along with use cases”