This blog focuses primarily on key value data stores, its example along with their architecture and features. Examples are Amazon Dynamo DB and Yahoo PNUTS( as a reference for geographic replication).
What do you mean by a database?
A database is any type of mechanism used for storing, managing, and retrieving information. It is a repository or collection of data.
A database’s implementation and how data is structured will determine how well an application will perform as it scales. There are two primary types of databases, relational and non-relational.
- Relational databases(SQL databases): they use the Structured Query Language to manage information storage and retrieval.
- Non-relational databases(NoSQL databases): NoSQL databases are often distributed databases where data is stored on multiple computers or nodes.
Each database type is optimized to support a specific type of workload. Matching an application with the appropriate database type is essential for highly performant and cost-efficient operation.
Why to use Non relational data bases?
While relational databases are highly-structured repositories of information, non-relational databases do not use a fixed table structure. They are schema-less.
Since it doesn’t use a predefined schema that is enforced by a database engine, a non-relational database can use structured, semi-structured, and unstructured data without difficulty.

NoSQL databases are popular with developers because they do not require an upfront schema design; they are able to build code without waiting for a database to be designed and built.
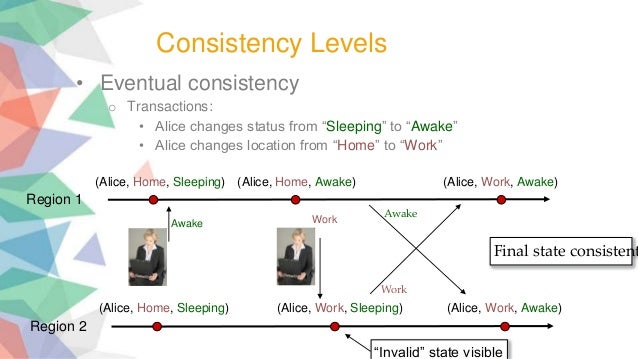
By relaxing consistency, distributed systems can be highly available and durable. It’s possible for data to be inconsistent; a query might return old or stale data. You might hear this phenomenon described as being eventually consistent. Over time, data that is spread across storage nodes will replicate and become consistent. What makes this behavior acceptable is that developers can anticipate this eventual consistency and allow for it.
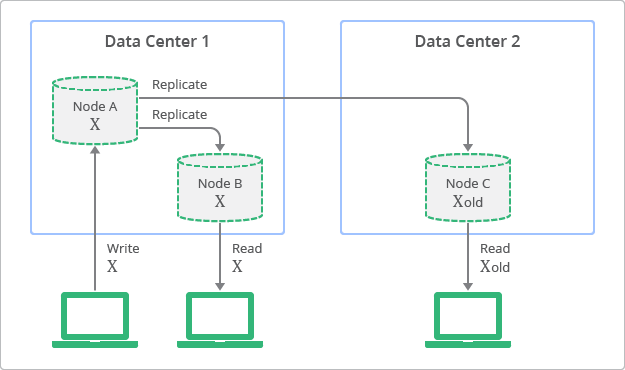
Scaling a NoSQL database is easier and less expensive than scaling a relational database because the scaling is horizontal instead of vertical. NoSQL databases generally trade consistency for performance and scalability.
NoSQL databases are often run in clusters of computing nodes. Data is partitioned across multiple computers so that each computer can perform a specific task independently of the others. Each node performs its task without having to share CPU, memory, or storage with other nodes. This is known as a shared-nothing architecture.
Key value data store:
Saves data as a group of key value pairs, which are made up of two data items that are linked. The link between the items is a “key” which acts as an identifier for an item within the data and the “value”that is the data that has been identified.

Key value systems treat the data as a single opaque collection which may have different fields for every record. Hence, they generally use much less memory while saving and storing the same amount of data, which in turn, increases the performance for certain workloads. In each key value pair,
- The key is represented by an arbitrary string
- The value can be any kind of data like an image, file, text or document
The value is stored as a blob requiring no upfront data modeling. This offers considerable flexibility and more closely follows modern concepts like object-oriented programming. As optional values are not represented by placeholders, it leads to less memory used to store. The storage of the value as a blob removes the need to index the data to improve performance. You cannot filter or control whats returned from a request based on the value because the value is opaque.
Scaling in Key value stores?
Key-value stores scale out by implementing partitioning, replication, and auto-recovery. The simplest way for key-value stores to scale up is to shard the entire key-space.
Replication can be done by the store itself or by the client.
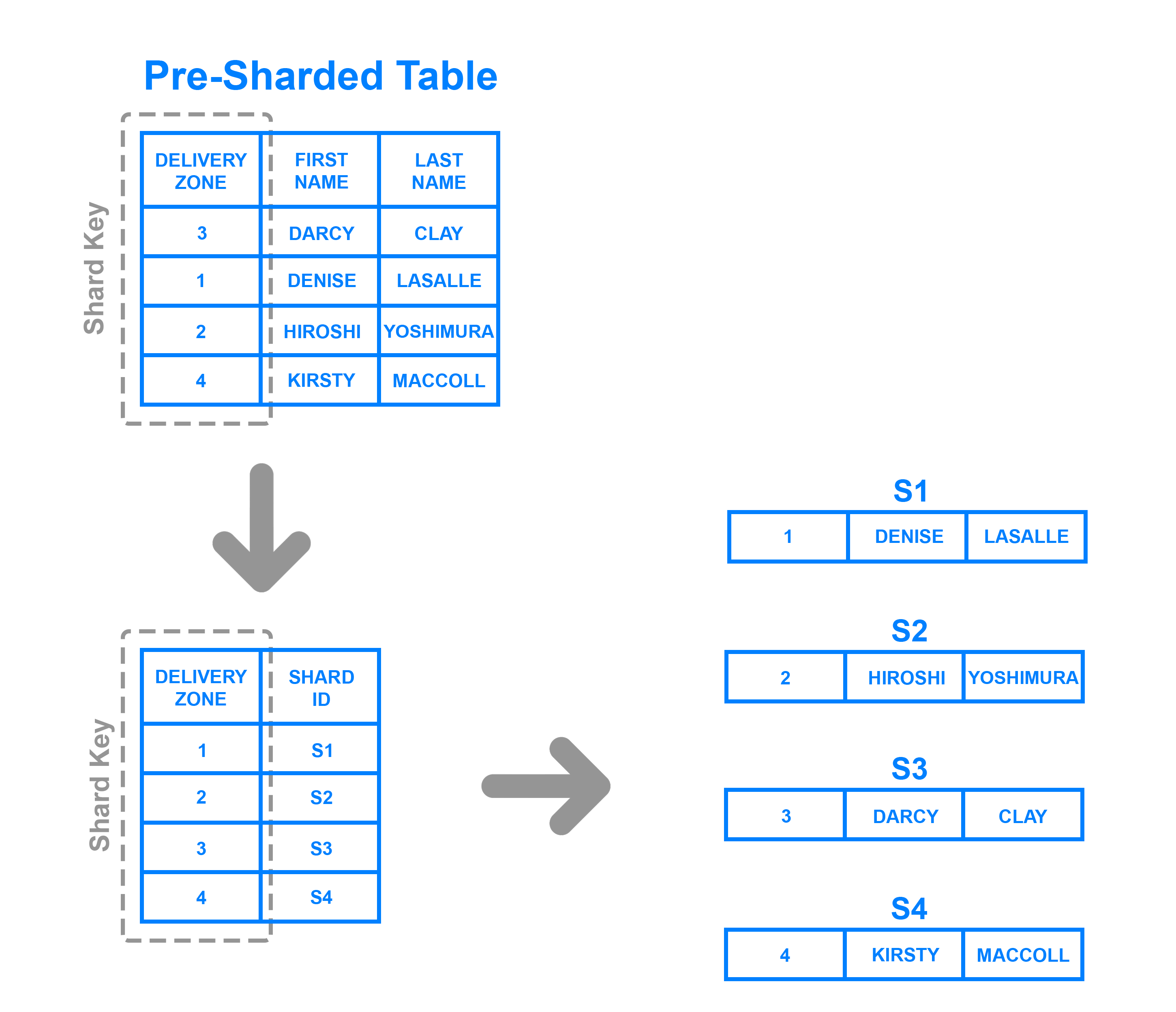
When to use key value stores ?
Key-value stores handle size well and are good at processing a constant stream of read/write operations with low latency making them perfect for,
- Session management at high scale
- User preference and profile stores
- Can effectively work as a cache for heavily accessed but rarely updated data
Advantages of Key value stores,
- For most key value stores, the secret to its speed lies in its simplicity. The path to retrieve data is a direct request to the object in memory or on disk.
- The relationship between data does not have to be calculated by a query language, there is no optimization performed.
- They can exist on distributed systems and don’t need to worry about where to store indexes, how much data exists on each system or the speed of a network with a distributed system they just work.
Disadvantages of Key value stores,
- No complex query filters
- All joins must be done in code
- No foreign key constraints
- No trigger
Example of Key Value Stores
A.Amazon Dynamo DB:
Peer to Peer key value database, each peer has its own instance of a specific database. It supports object versioning and application assisted conflict resolution. It uses a synthesis of well-known techniques to achieve scalability and availability,
- Data is partitioned and replicated using consistent hashing.
- Consistency if facilitated by version clock and object versioning.
- Consistency among replicas is maintained by a decentralized replica synchronization protocol.
- Gossip protocol is used for failure detection.
Dynamo treats both the key and the object supplied by the caller as an opaque array of bytes. It applies a MD5 hash on the key to generate a 128 bit identifier, which is used to determine the storage nodes that are responsible for serving the key.
How to do Partitioning using consistent hashing?
Dynamo’s partitioning scheme relies on consistent hashing to distribute the load across multiple storage hosts. The output range of a hash function is treated as a fixed circular space or ring.

Each node in the system is assigned a random value withing this space which represents its position on the ring. Keys and nodes mapping to same ID space-idea. Each data item is assigned to a node by,
- Hashing the data item’s key to yield it’s position on the ring
- and then walking the ring clockwise to find the first node with a position larger than the item’s position
The principle advantage of consistent hashing is that departure or arrival of a node only affects its immediate neighbors and other nodes remain unaffected.
Advantages of consistent hashing:
- This works well, except the size of the intervals assigned to each cache is pretty hit and miss.
- Since it is essentially random it is possible to have a very non-uniform distribution of objects between caches.
How to address the non uniform distribution of objects between caches?
Dynamo adds virtual nodes in the hash ring where 1 physical node can actually represent multiple virtual nodes by using multiple hash functions. This leads to an enriched hashed ring with data evenly distributed across the nodes. This node is also called the coordinator node which is responsible for request handling and data replication for the key.
A virtual node looks like a single node in the system, but each node can be responsible for more than one virtual node. Effectively, when a new node is added to the system, it is assigned multiple positions in the ring.

Virtual Nodes advantages:
- If a node becomes unavailable, the load handled by this node is evenly dispersed across the remaining available nodes.
- When a node becomes available again, or a new node is added to the system, the newly available node accepts a roughly equivalent amount of load from each of the other available nodes.
- The number of virtual nodes that a node is responsible can decided based on its capacity, accounting for heterogeneity in the physical infrastructure.
How to deal with Data replication ?
To achieve high availability and durability, Dynamo replicates its data on multiple hosts. Each data item is replicated at N hosts, where N is a parameter configured “per-instance”.
Each key k is assigned to a coordinator node. The coordinator is in charge of the replication of the data items that fall within its range (ring). The coordinator locally store each key within its range, And in addition, it replicates these keys at the N-1 clockwise successor nodes in the ring.
- The list of nodes that is responsible for storing a particular key is called the preference list.
- The system is designed so that every node in the system can determine which nodes should be in this list for any particular key.
- To account for node failures, preference list contains more than N nodes. To avoid that with “virtual nodes” a key k is owned by less than N physical nodes, the preference list skips some nodes.
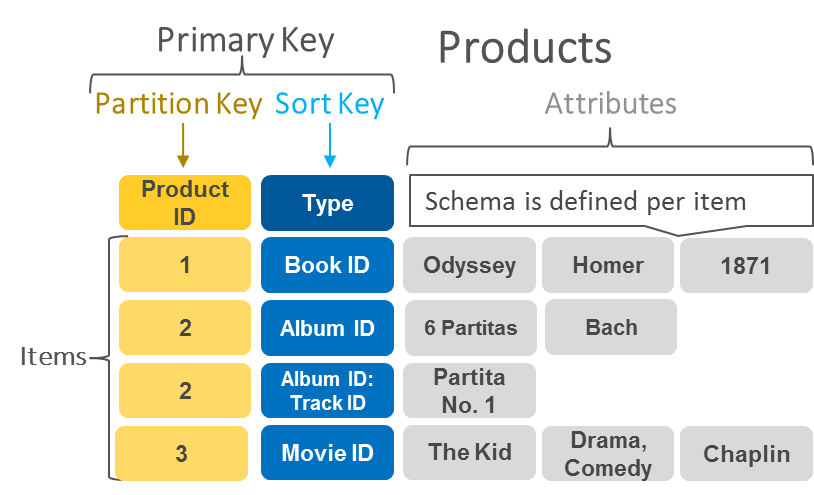
In its simplest form, you can just provide a table name and a primary key, which is used to partition data across hosts for scalability and availability. You can then accept any remaining defaults and create your database, it’s as simple as that.

The default option provides no secondary index. However, you can add them here if required. DynamoDB lets you create additional indexes so that you can run queries to search your data by other attributes. There are a couple of big differences in how indexes operate in DynamoDB.
- Each query can only use one index. If you want to query and match on two different columns, you need to create an index that can do that properly.
- When you write your queries, you need to specify exactly which index should be used for each query. It’s not like a relational database that has a query analyzer, which can decide which indexes to use for our query.
DynamoDB has two different kinds of secondary indexes,
- global indexes let you query across the entire table to find any record that matches a particular value
- local secondary indexes can only help find data within a single partition key.
When you create a table in DynamoDB, you need to tell AWS how much capacity you want to reserve for the table. You don’t need to do this for disk space as DynamoDB will automatically allocate more space for your table as it grows. However, you do need to reserve capacity for input and output for reads and writes. Amazon charges you based on the number of read capacity units and write capacity units that you allocate.
Through the use of the key management service, KMS, you are able to select either a customer managed or AWS managed CMK to use for the encryption of your table instead of the default keys used by DynamoDB.
Some of the advantages of DynamoDB
- It’s fully managed by AWS, you don’t have to worry about backups or redundancy.
- DynamoDB tables are schema less so you don’t have to define the exact data model in advance.
- DynamoDB is designed to be highly available and your data is automatically replicated across three different availability zones within a geographic region.
- DynamoDB is designed to be fast, read and writes take just a few milliseconds to complete and DynamoDB will be fast no matter how large your table grows, unlike relational database, which can slow down as the table gets large.
Downsides to using DynamoDB too.
- Your data is automatically replicated. Many operations will make sure that they’re always working on the latest copy of your data, but there are certain kinds of queries and table scans that may return older versions of data before the most recent copy.
- DynamoDB’s queries aren’t as flexible as what you can do with SQL. You’ll have to do more of the computation in your application code.
- Although DynamoDB performance can scale up as your needs grow, your performance is limited to the amount of read and write throughput that you’ve provisioned for each table.
For more information about Dynamo db,
- https://www.dynamodbguide.com/what-is-dynamo-db
- https://medium.com/@uditsharma/internals-of-dynamodb-b3b7912256ae
- https://cloudacademy.com/blog/dynamodb-replication-and-partitioning-part-4/
B.Yahoo PNUTS:
PNUTS’s data model is flexible. Each record consists of a key, simple metadata, and the record body. PNUTS tables are horizontally partitioned into tablets.
Each tablet contains some number of records in their entirety. PNUTS supports a simple set of operations against its tables: insert, update, read, and delete of single records, as well as range scans against multiple records.
It supports ordered tables that organize records physically by key to enable range scans, as well as secondary indexes.
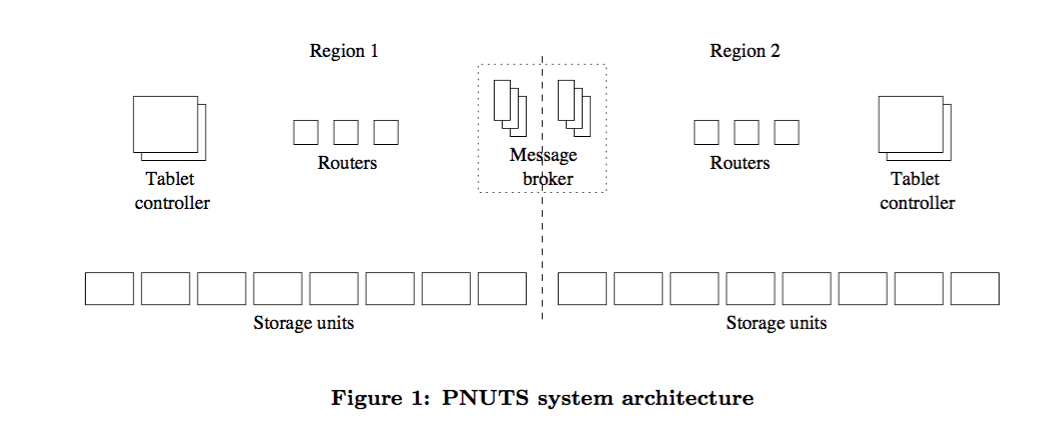
PNUTS Architecture?

- Each Storage unit has many tablets.
- Tablets may grow over time
- Shed load by moving tablets to other servers
- Yahoo Message Bus(YMB) is a distributed publish-subscribe service.
- Guarantees delivery once a message is published
- Logging at site where message is published, and at other sites when received.
- Guarantees messages published to a particular cluster will be delivered in same order at all other clusters
- Record updates are published to YMB by master copy
- All Replicas subscribe to the updates and get them in same order for a particular record.
- Guarantees delivery once a message is published
Consistency in PNUTS?
PNUTS was one of the earliest systems to natively support geographic replication, using asynchronous replication to avoid long write latency. Geographic replication ensures that PNUTS is available under various failure conditions.
PNUTS need not synchronously maintain a record and its replicas, but all follow the same timeline of states. It doesn’t allow records to go backward in time, nor states to appear that other concurrent writes will discard. PNUTS must preserve some degree of consistency and availability during partition failure cases. Asynchronous geographic replication gives us latency reads and writes.
PNUTS implements its default timeline consistency using record mastery. No matter where they originate, PNUTS forwards all writes to a record to a single region where that record is mastered.
Record and Tablet Master ship?
- Data in PNUTS is replicated across sites
- Hidden field in each record stores which copy is the master copy
- updates can be submitted to any copy
- forwarded to master, applied in order received by master
- Record also contains origin of last few updates
- Mastership can be changed by current master, based on this information
- Mastership change is simply a record update
- Tablets mastership
- Required to ensure primary key consistency
- Can be different from record mastership
Query Processing in Yahoo PNUTS,
- Range scan can span tablets
- Only one tablet scanned at a time
- Client may not need all results at once
- Continuation object returned to client to indicate where range scan should continue.
- Notification
- One pub-sub topic per tablet
- Client knows about tables, does not know about tablets
- Automatically subscribed to all tablets, even as tablets are added/removed.
- Usual problem with pub-sub: undelivered notifications, handled in usual way

{kind=link}
One thought on “Introduction to Key value data store along with use cases”