This blog focuses primarily on document value data stores, its example along with their architecture and features. Example used is Mongo DB.
What do you mean by a database?
A database is any type of mechanism used for storing, managing, and retrieving information. It is a repository or collection of data.
A database’s implementation and how data is structured will determine how well an application will perform as it scales. There are two primary types of databases, relational and non-relational.
- Relational databases(SQL databases): they use the Structured Query Language to manage information storage and retrieval.
- Non-relational databases(NoSQL databases): NoSQL databases are often distributed databases where data is stored on multiple computers or nodes.
Each database type is optimized to support a specific type of workload. Matching an application with the appropriate database type is essential for highly performant and cost-efficient operation.
Why to use Non relational data bases?
While relational databases are highly-structured repositories of information, non-relational databases do not use a fixed table structure. They are schema-less.
Since it doesn’t use a predefined schema that is enforced by a database engine, a non-relational database can use structured, semi-structured, and unstructured data without difficulty.

NoSQL databases are popular with developers because they do not require an upfront schema design; they are able to build code without waiting for a database to be designed and built.
By relaxing consistency, distributed systems can be highly available and durable. It’s possible for data to be inconsistent; a query might return old or stale data. You might hear this phenomenon described as being eventually consistent. Over time, data that is spread across storage nodes will replicate and become consistent. What makes this behavior acceptable is that developers can anticipate this eventual consistency and allow for it.
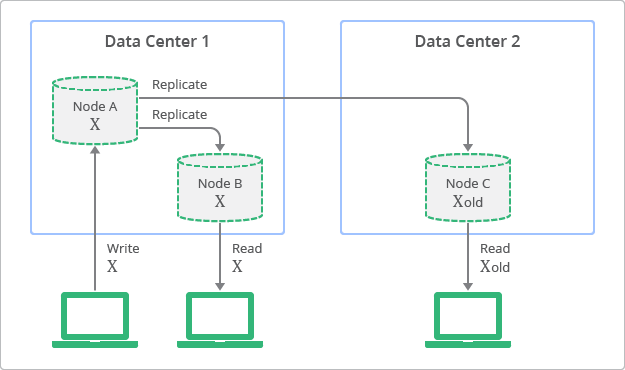
Scaling a NoSQL database is easier and less expensive than scaling a relational database because the scaling is horizontal instead of vertical. NoSQL databases generally trade consistency for performance and scalability.
NoSQL databases are often run in clusters of computing nodes. Data is partitioned across multiple computers so that each computer can perform a specific task independently of the others. Each node performs its task without having to share CPU, memory, or storage with other nodes. This is known as a shared-nothing architecture.
Document Data store:
A document database is a type of non relational database that is designed to store and query data as JSON-like documents. Document databases make it easier for developers to store and query data in a database by using the same document-model format they use in their application code.
They are flexible, semi structured, and hierarchical nature of documents and document databases allows them to evolve with applications’ needs. The document model works well with use cases such as catalogs, user profiles, and content management systems where each document is unique and evolves over time.
A document database is, at its core, a key/value store with one major exception. Instead of just storing any blob in it, a document db requires that the data will be store in a format that the database can understand.
So a document database would store the employee information as one document, along with the metadata, enabling the search based on the fields of the entity. Unlike relational databases, document stores are not strongly typed. Document databases get their type information from the data itself, normally store all related information together, and allow every instance of data to be different from any other.

The metadata also allows the document format to be changed at any time without affecting the existing records. Fields can be added at any time, anywhere, with no need to change the physical storage.
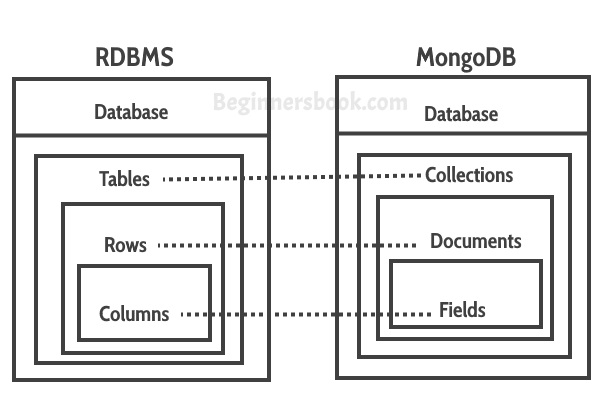
Terminologies in document data store?
- A table is called a collection
- A row is called a document
- A column in called a field
Advantages of Document Data stores:
- Instead of grabbing the data from the hard disk during a query, it grabs the data from the RAM and query returns come back much quicker.
- Very dynamic schematics architecture for unstructured data and storage options
- Sharding for horizontal scalability
- Replication is managed internally, so chances of accidental loss of data is negligible.
Disadvantages of Document data stores:
- No support for transactions, which could lead to data corruption
- Pulling data from several collections requires a number of queries, which will inevitably lead to messy code and long turn-around times.
- The relationships are not typically well-defined and the resulting duplicate data sets can be hard to handle.
- No views, triggers, scripts or stored procedure.
Examples for Document data store
A.Mongo DB
MongoDB stores data records as documents which are gathered together in collections. Collections are analogous to tables in relational databases. A database stores one or more collections of documents.
A record in MongoDB is a document, which is a data structure composed of field and value pairs. MongoDB documents are similar to JSON objects. The values of fields may include other documents, arrays, and arrays of documents.
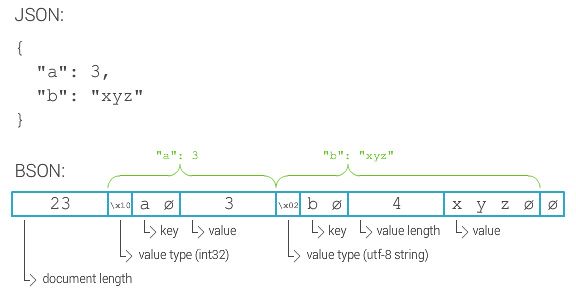
MongoDB stores data records as BSON documents. BSON is a binary representation of JSON documents, though it contains more data types than JSON.

Some documents created by internal MongoDB processes may have duplicate fields, but no MongoDB process will ever add duplicate fields to an existing user document.
Data models?
MongoDB allows related data to be embedded within a single document, since there is no foreign key.
1.Embedded documents capture relationships between data by storing related data in a single document structure. MongoDB documents make it possible to embed document structures in a field or array within a document.
These schema are generally known as “de-normalized” models, and take advantage of MongoDB’s rich documents
2. References store the relationships between data by including links or references from one document to another. Applications can resolve these references to access the related data.
Normalized data models describe relationships using references between documents. We use normalized data models for,
- When embedding would result in duplication of data but would not provide sufficient read performance advantages to outweigh the implications of the duplication.
- To represent more complex many-to-many relationships.
- To model large hierarchical data sets.

Architecture?
- Shards: mongod servers store the data
- Multiple shard servers form a replica set
- Replica set maintain same replica of data
- Routers: mongos interfaces with clients and routers operations to appropriate shards
- Config: Stores collection level metadata

Indexes?
Indexes support the efficient execution of queries in MongoDB. Without indexes, MongoDB must perform a collection scan. If an appropriate index exists for a query, MongoDB can use the index to limit the number of documents it must inspect.
Indexes are special data structures that store a small portion of the collection’s data set in an easy to traverse form. The index stores the value of a specific field or set of fields, ordered by the value of the field.
Use indexes to improve performance for common queries. Build indexes on fields that appear often in queries and for all operations that return sorted results. MongoDB automatically creates a unique index on the _id field.

As you create indexes, consider the following behaviors of indexes:
- Adding an index has some negative performance impact for write operations. For collections with high write-to-read ratio, indexes are expensive since each insert must also update any indexes.
- Collections with high read-to-write ratio often benefit from additional indexes. Indexes do not affect un-indexed read operations.
- When active, each index consumes disk space and memory. This usage can be significant and should be tracked for capacity planning, especially for concerns over working set size.
Replication?
Replication provides redundancy and increases data availability. With multiple copies of data on different database servers, replication provides a level of fault tolerance against the loss of a single database server.
In some cases, replication can provide increased read capacity as clients can send read operations to different servers. Maintaining copies of data in different data centers can increase data locality and availability for distributed applications. You can also maintain additional copies for dedicated purposes, such as disaster recovery, reporting, or backup.

- The primary node receives all write operations and records all changes to its data sets in its operation log.
- The secondaries replicate the primary’s oplog and apply the operations to their data sets such that the secondaries’ data sets reflect the primary’s data set.
- An arbiter participates in elections but does not hold data .
An arbiter will always be an arbiter whereas a primary may step down and become a secondary and a secondary may become the primary during an election.
Sharding?
MongoDB uses sharding to provide horizontal scaling. These clusters support deployments with large data sets and high-throughput operations. Sharding allows users to partition a collection within a database to distribute the collection’s documents across a number of shards.
To distribute data and application traffic in a sharded collection, MongoDB uses the shard key. Selecting the proper shard key has significant implications for performance, and can enable or prevent query isolation and increased write capacity. It is important to consider carefully the field or fields to use as the shard key.


{kind=link}
{kind=link}
One thought on “Introduction to Document value data store along with a use case”