In this blog, i focus on Hive, features and limitations of hive, architecture of hive and Joins in hive. Let’s start by understanding what is hive,
Q.What is Hive?
Hive is a data warehousing facility provided by Apache. Hive is built on top of the Hadoop Distributed File System (HDFS) to write, read, querying, and manage large structured or semi-structured data in distributed storage systems such as HDFS.
Hive provides Hive Query Language (HiveQL) that is like normal SQL in RDBMS. Like SQL. Each HiveQL will be converted to a MapReduce job in the backend.
Features of Hive :
- Hive stores are raw and processed dataset in Hadoop.
- It is designed for Online Transaction Processing (OLTP). OLTP is the systems that facilitate high volume data in very less time with no reliance on the single server.
- It is fast, scalable and reliable.
- ETL tasks and other analysis easier.
Limitations of Hive:
- Hive doesn’t support subqueries.
- Hive surely supports over-writing, but unfortunately, it doesn’t support deletion and updates.
- Hive is not designed for OLTP, but it is used for it.
Data in Hive Organised Into:
A. Tables: Each table has a corresponding directory in HDFS. Data is serialised and stored as files within that directory.
- Hive has default serialisation built in which supports compression and lazy de-serialisation. Users can specify custom serialisation and de-serialisation schemes.
B. Partitions: Each table can be broken into participation, each participation determine distribution of data within sub directories.
C. Buckets: data in each partition divided into buckets based on a hash function of the column. Each bucket is stored as a file in partition directory.
- H(column) mod numBuckets = bucket number

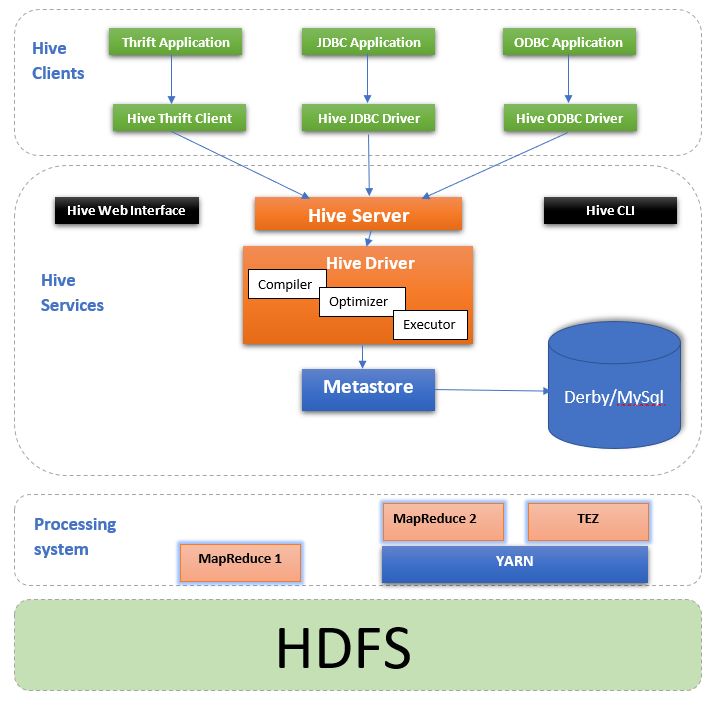
Major Hive Architecture Components:
A. Meta Store: Repository storing the metadata is called the hive meta store. The metadata consists of the different data about the tables like its location, schema, information about the partitions, which helps to monitor variously distributed data progress in the cluster.
B. Driver: On execution of the Hive query language statement, the driver receives the statement, and it controls it for the full execution cycle. Along with the execution of the statement, the driver also stores the metadata generated from the execution.
It also creates sessions to monitor the progress and life cycle of different executions. After the completion of the reducing operation by the Map Reduce job the driver collects all the data and results of the query.
C. Compiler: It is used for translating the Hive query language into MapReduce input. It invokes a method that executes the steps and tasks that are needed to read the HiveQL output as needed by the MapReduce.
D. Optimiser: The main task of the optimiser is to improve the efficiency and scalability, creating a task while transforming the data before the reduce operation. It also performs transformations like aggregation, pipeline conversion by a single join for multiple joins.
E. Executor: The main task of the executor is to interact with Hadoop job tracker for scheduling of tasks ready to run.
- Thrift server is used by other clients to interact with the Hive engine.
- The user interface and the command-line interface helps to submit the queries as well as process monitoring and instructions so that external users can interact with the hive.
Different Modes of Hive
Hive can operate in two modes depending on the size of data nodes in Hadoop:
A. Local mode: If the Hadoop installed under pseudo mode with having one data node we use Hive in this mode. If the data size is smaller in term of limited to single local machine, we can use this mode processing will be very fast on smaller data sets present in the local machine.
B. Map reduce mode: If Hadoop is having multiple data nodes and data is distributed across different node we use Hive in this model. It will perform on large amount of data sets and query going to execute in parallel way. Processing of large data sets with better performance can be achieved through this mode
By default, it works on Map Reduce mode and for local mode you can have the following setting.
Joins in Hive:
Map join is a feature used in Hive queries to increase its efficiency in terms of speed. Join is a condition used to combine the data from 2 tables. So, when we perform a normal join, the job is sent to a Map- Reduce task which splits the main task into 2 stages – “Map stage” and “Reduce stage”.
- The Map stage interprets the input data and returns output to the reduce stage in the form of key-value pairs. A mapper’s job during Map stage is to red the data from join tables and to return the join key and join value pair into an intermediate file.
- This next goes through the shuffle stage where they are sorted and combined.
- The reducer takes this sorted value and completes the join job. The reducer’s job during reduce stage is to take this sorted result as input and complete the task of join.
Map Join Hive
Map join is a type of join where a smaller table is loaded in memory and the join is done in the map phase of the As no reducers are necessary, map joins are way faster than the regular joins. It lets a table to be loaded into memory so that a join could be performed within a mapper without using a Map/Reduce step.
A table can be loaded into the memory completely within a mapper without using the Map/Reducer process. Basically, it involves performing joins between 2 tables by using only the Map phase and skipping the Reduce phase.
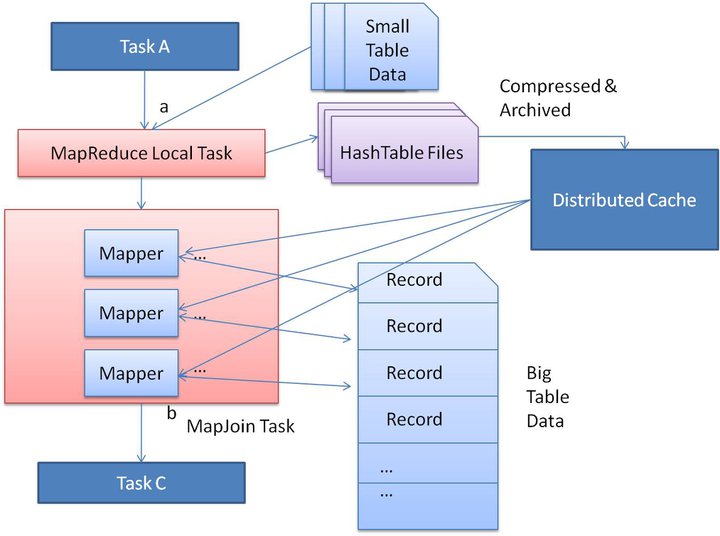
Assume that we have two table of which one of them is a small table. When we submit a map reduce task, a Map reduce local task will be created before the original join Map reduce task which will read data of the small table from HDFS and store it into an in-memory hash table. After reading it serialises the in memory hash-table into a hash table file.
In the next stage, when the original Map reduce task is running, it does the data in the hash table file to the Hadoop distributed cache, which populates these files to each mapper’s local disk. So all the mappers can load this persistent hash table file back into the memory and do the jon work as before. The execution flow of the optimised map join is shown in the figure below. After optimisation, the small table needs to be read just once. Also if multiple mapper are running on the same machine, the distributed cache only needs to push one copy of hte has table file to this machine.
Advantages of using map side join:
- Map-side join helps in minimizing the cost that is incurred for sorting and merging in the shuffle and reduce stages.
- Map-side join also helps in improving the performance of the task by
- decreasing the time to finish the task.
Disadvantages of Map-side join:
- Map side join is adequate only when one of the tables on which you
perform map-side join operation is small enough to fit into the
memory. - Hence it is not suitable to perform map-side join on the
tables which are huge data in both of them.
Hive Views:
Apache Hive supports the features of views, which are logical constructs and treated the same as tables. It makes it possible to save the query, on which all DML (Data Manipulation Language) commands can be performed. It is similarly used as views in SQL; however, views are created based on user requirement.
In Hive, the query referencing the view is executed first, and then the result obtained is used in the rest of the query. Also, the Hive’s query planner helps in the execution plan.
One of the major reasons for using it is to reduce the complexity of a query. There are many times when long or complicated queries become difficult to manage or develop because of too many nested queries. By turning the nested queries into views, end users can encapsulate a query’s complexity and create re-usable parts.
Views are also widely used to filter or restrict data from a table based on the value of one or more columns. The use case of restricted data is when we don’t want the end-user to see all the base table information.
Hive Indexes:
Indexes are a pointer or reference to a record in a table as in relational databases.
Indexing is a relatively new feature in Hive. In Hive, the index table is different than
the main table. Indexes facilitate in making query execution or search operation faster.
With the petabytes of data that needs to be analyzed, querying Hive tables with millions of records and hundreds of columns becomes time-consuming. Indexing a table helps in performing any operation faster.
First, the index of the column is checked and then the operation is performed on that column only. Without an index, queries involving filtering with the “WHERE” clause would load an entire table and then process all the rows. Indexing in Hive is present only for ORC file format, as it has a built-in index with it. There are two types of indexing in Hive:
- Bitmap Indexing: This is used with columns having a few distinct values. It is known to store both the indexed column’s value and the list of rows as a bitmap.
- Compact Indexing: This type of indexing is known to store the column value and storage blockid.
For more information about Hadoop and HDFS,

One thought on “Introduction to Hive(A SQL layer above hadoop)”