In this blog, i focus on Apache Spark , features and limitations of Apache Spark , architecture of Apache Spark, architecture of SparkQL, and architecture of Spark MLib . Let’s start by understanding what is Apache Spark,
Q.What is Apache Spark?
Apache Spark is a unified computing engine and a set of libraries for parallel data processing on computer clusters.
Why Apache Spark?
- Fast Processing: Spark contains Resilient Distributed datasets (RDD) which saves time taken in reading and writing opertions and hence, hence it runs almost ten to hundred times faster than hadoop.
- In-memory computing: In spark, data is stored in the RAM, so it can access the data quickly and accelerate the speed of analytics.
- Flexible: Spark supports multiple languages and allows the developers to write applications in Java, Scala, R or Python.
- Fault tolerance: Spark contains Resillent Distributed Datasets(RDD) that are designed to handle the failure of any worker node in the cluster. THus, it ensures that the loss of data reduces to zero.
- Better analytics: Spark has a rich set of SQL queries, machine learning algorithms, complex analytics. With all these functionalities can be performed better.
Shortcoming of MapReduce:
- Forces your data processing into Map and Reduce
- Other workflows missing include join, filter, flatMap, groupByKey, union, intersection, …
- Based on “Acyclic Data Flow” from Disk to Disk (HDFS)
- Read and write to Disk before and after Map and Reduce (stateless machine)
- Not efficient for iterative tasks, i.e. Machine Learning
- Only Java natively supported
- Only for Batch processing
- Interactivity, streaming data
How to does Apache spark solve these shortcomings?
- Capable of leveraging the Hadoop ecosystem, e.g. HDFS, YARN, HBase, S3, …
- Has many other workflows, i.e. join, filter, flatMapdistinct, groupByKey, reduceByKey, sortByKey, collect, count, first…
- In-memory caching of data (for iterative, graph, and machine learning algorithms, etc.)
- Native Scala, Java, Python, and R support
- Supports interactive shells for exploratory data analysis
- Spark API is extremely simple to use

Architecture of Spark
Spark is accessible, intense, powerful and proficient Big Data tool for handling different enormous information challenges. Apache Spark takes after an ace/slave engineering with two primary Daemons and a Cluster Manager
- Master Daemon – (Master/Driver Process)
- Worker Daemon – (Slave Process)

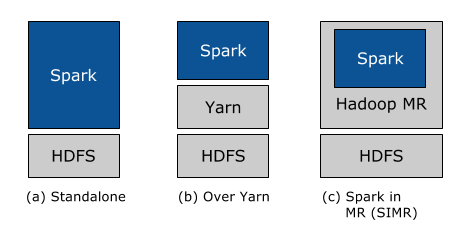
A spark cluster has a solitary Master and many numbers of Slaves/Workers. The driver and the agents run their individual Java procedures and users can execute them on individual machines. Below are the three methods of building Spark with Hadoop Components –
- Standalone – The arrangement implies Spark possesses the place on the top of HDFS(Hadoop Distributed File System) and space is allotted for HDFS, unequivocally. Here, Spark and MapReduce will run one next to the other to covering all in the form of Cluster.
- Hadoop Yarn – Hadoop Yarn arrangement implies, basically, Spark keeps running on Yarn with no pre-establishment or root get to required. It incorporates Spark into the Hadoop environment or the Hadoop stack. It enables different parts to keep running on the top of the stack having an explicit allocation for HDFS.
- Spark in MapReduce – Spark in MapReduce is utilized to dispatch start work notwithstanding independent arrangement. With SIMR, the client can begin Spark and uses its shell with no regulatory access.
Abstractions in Spark Architecture
In this architecture, all the components and layers are loosely coupled. These components are integrated with several extensions as well as libraries. There are mainly two abstractions on which spark architecture is based. They are:
- Resilient Distributed Datasets (RDD): These are the collection of object which is logically partitioned.
- It supports in-memory computation over spark cluster. Spark RDDs are immutable in nature.
- It supports Hadoop datasets and parallelized collections.
- Hadoop Datasets are created from the files stored on HDFS. Parallelized collections are based on existing scala collections.
- As RDDs are immutable, it offers two operations transformations and actions.
- Directed Acyclic Graph (DAG): Directed- Graph which is directly connected from one node to another. This creates a sequence.
- Acyclic – It defines that there is no cycle or loop available.
- Graph – It is a combination of vertices and edges, with all the connections in a sequence
- We can call it a sequence of computations, performed on data. In this graph, edge refers to transformation on top of data. while vertices refer to an RDD partition. This helps to eliminate the Hadoop mapreduce multistage execution model. It also provides efficient performance over Hadoop.

Spark Execution Flow :
- Application Jar: User program and its dependencies except Hadoop & Spark Jars bundled into a Jar file.
- Driver Program: The process to start the execution (main() function)
- Main process co-ordinated by the SparkContext object.
- Allows to configure any spark process wth specific parameters
- Spark actions are executed in the Driver
- Cluster Manager: An external service to manage resources on the cluster ( YARN)
- External services for acquring resources on the cluster
- Variety of cluster managers such as Local, Standalone, and Yarn
- Deploy Mode
- Cluster: Driver inside the cluster, framework launches the driver inside of the cluster.
- Client: Driver outside of cluster
- Worker Node: any node that run the application program in cluster.
- Executor: A process launched for an application on a worker node that run tasks and keeps data in memory or disk storage across them. Each application has its own executors.
- Task: a unit of work that will be sent to executor
- Job: a parallel computation consisting of multiple tasks that gets spawned in response to a spark action.
- Stage: Each job is divided into smaller set of tasks called stages that is sequential and depend on each other
- Spark Context: represents the connection to a spark cluster, and can be used to create RDDs accumulator and broadcast variables on that cluster.
- Main entry point for Spark functionality
- Represents the connection to a spark cluster
- Tells spark how & where to access a cluster
- Can be used to create RDDs, accumulators and broadcast variables on that cluster.
Resillient Distributed dataset (RDD)
Resilient Distributed dataset (RDD) is a basic abstraction in spark. Immutable, Partitioned collection of elements that can be operated in parallel.
Main characteristics of RDD
- A list of partitions
- A function for computing each split
- A list of dependencies an other RDDs
- Optionally,a partioner for key-value RDDs.
- A list of preferred locations to compute each split on.
Custom RDD can be also implemented (by overriding functions)

- Transformations: These are functions that accept the existing RDDs as input and outputs one or more RDDs. However, the data in the existing RD in Spark does not change as it is immutable.
- These transformation are executed when they are invoked or called. Every time transformation are applied, a new RDD is created.
- Actions: These are functions that return the end result of RDD computations. It uses a lineage graph to load data onto the RDD in particular order. After all of the transformations are done, actions return the final result to the Spark driver. Actions are Operations that provide non-RDD values.
Features of RDD
- RDD in Apache Spark is an immutable collection of objects which computes on the different node of the cluster.
- Resilient, i.e. fault-tolerant with the help of RDD lineage graph(DAG) and so able to recompute missing or damaged partitions due to node failures.
- Distributed, since Data resides on multiple nodes.
- Dataset represents records of the data you work with. The user can load the data set externally which can be either JSON file, CSV file, text file or database via JDBC with no specific data structure.
- each and every dataset in RDD is logically partitioned across many servers so that they can be computed on different nodes of the cluster. RDDs are fault tolerant i.e. It posses self-recovery in the case of failure.
Dependencies of RDD
- Narrow dependencies: Each parition of the parent RDD is used by at most one parition of the child RDD. Task can be executed locally and we don’t have to shuffle.
- Pipelined execution
- Efficient recovery
- No shuffling
- Wide dependencies: multiple child partitions may depend on one partition of the parent RDD. his means we have to shuffle data unless the parents are hash-partitioned.
- Requires shuffling unless parents are hash-partitioned
- Expensive to recover

How to create a RDD?
- By loading an external dataset: You can load an external file onto an RDD. The types of you can load are csv, txt , json, etc. Here is the example of loading a text file onto an RDD.
- By paralleling the collection of objects: When spark’s parallelize method is applied to a group of elements, a new distributed dataset is created. This dateset is an RDD.
- By Performing Transformation on the existing RDDs: One or more RDDs can be created by performing transformations on the existing RDDs as mentioned earlier in this tutorial page.
Spark SQL
Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
Spark SQL originated as Apache Hive to run on top of Spark and is now integrated with the Spark stack. Apache Hive had certain limitations Spark SQL was built to overcome these drawbacks and replace Apache Hive.
Spark SQL is faster than Hive when it comes to processing speed. Spark SQL is an Apache Spark module used for structured data processing, which:
- Acts as a distributed SQL query engine
- Provides DataFrames for programming abstraction
- Allows to query structured data in Spark programs
- Can be used with platforms such as Scala, Java, R, and Python.
Features of Spark SQL:
- Integrated − Seamlessly mix SQL queries with Spark programs. Spark SQL lets you query structured data as a distributed dataset (RDD) in Spark, with integrated APIs in Python, Scala and Java. This tight integration makes it easy to run SQL queries alongside complex analytic algorithms.
- Unified Data Access − Load and query data from a variety of sources. Schema-RDDs provide a single interface for efficiently working with structured data, including Apache Hive tables, parquet files and JSON files.
- Hive Compatibility − Run unmodified Hive queries on existing warehouses. Spark SQL reuses the Hive frontend and MetaStore, giving you full compatibility with existing Hive data, queries, and UDFs. Simply install it alongside Hive.
- Standard Connectivity − Connect through JDBC or ODBC. Spark SQL includes a server mode with industry standard JDBC and ODBC connectivity.
- Scalability − Use the same engine for both interactive and long queries. Spark SQL takes advantage of the RDD model to support mid-query fault tolerance, letting it scale to large jobs too. Do not worry about using a different engine for historical data.
Limitations of a Apache Hive:
- Hive uses MapReduce which lags in performance with medium and small sized datasets.
- No resume capability
- Hive cannot drop encrypted database
Spark SQL was built to overcome the limitations of Apache Hive running on top of Spark. Spark SQL uses the metastore services of Hive to query the data stored and manged by Hive.
Spark SQL Architecture
- Language API: Spark is very compatible as it supports languages like Python, Scala and Java.
- Schema RDD: As Spark SQL works on schema, tables and records you can use Schema RDD or dataframe as a temporary table.
- Data Sources: Spark SQL supports multiple data sources like JSON, Cassandra database, Hive tables.
- Data Source API is used to read and store structure and semi structured data into Spark SQL:
- Structured/Semi-structure data
- Multiple formats
- 3 rd party integrations
- DataFrame APi converts the data that is read through Data source API into tabular colmns to help perform SQL operations.
- Distributed collection of data organized into named columns
- Equivalent to a relational table in SQL
- Lazily evaluated
- SQL Interpreter and Optimised handles the functional programming part of Spark SQL. it transforms the Data frames RDDs to get the required results in the required formats.
- Functional programming
- transforming trees
- Faster than rdds
- Processes all size data
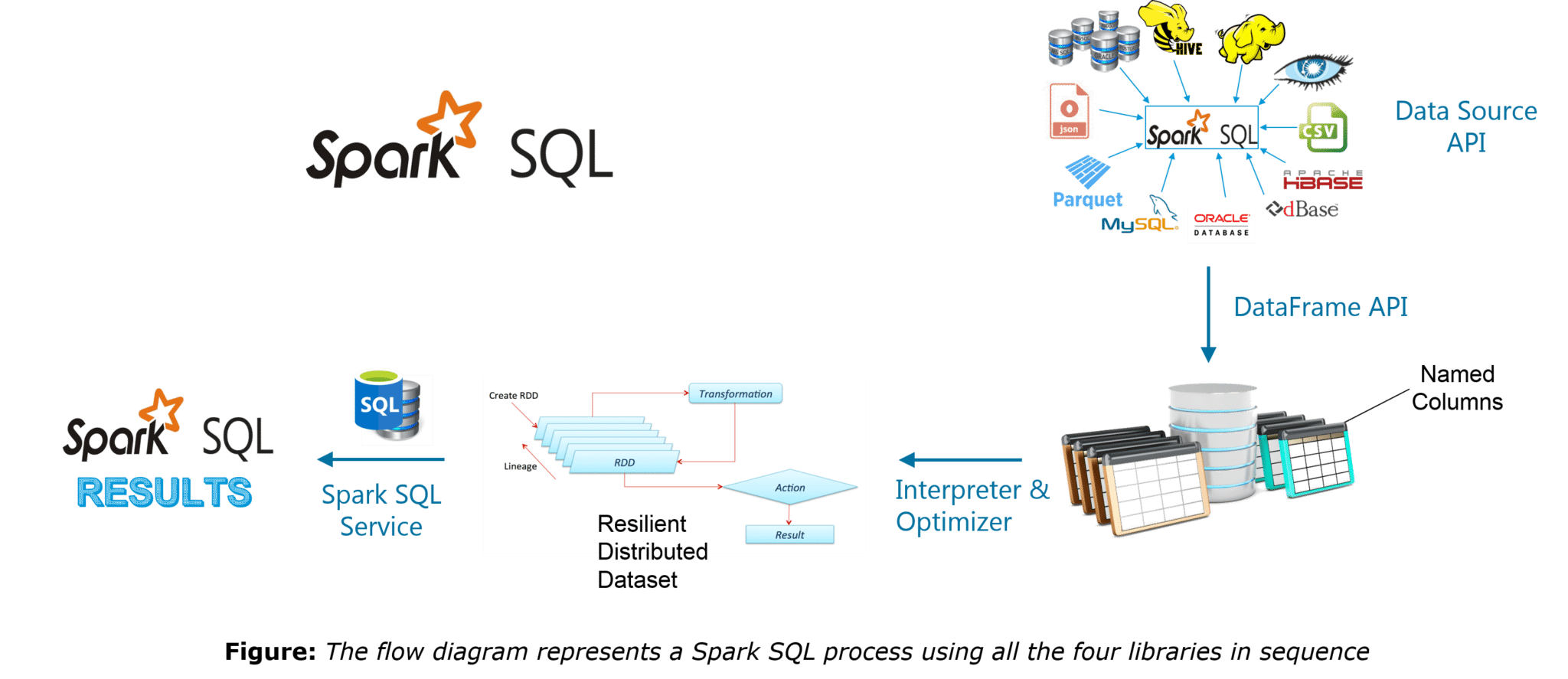
SQL service is the entry point for working along structured data in spark, and is used to fetch the result from the interpreted and optimised data.
Spark MLib
Mlib stands for Machine learnign library in Spark. The goal of this library is to make practical machine learning scalable and easy to implement.
It contains fast and scalable implementations of standard machine learning algorithms. Through Spark MLlib, data engineers and data scientists have access to different types of statistical analysis, linear algebra and various optimization primitives. Spark Machine Learning library MLlib contains the following applications
- Collaborative Filtering for Recommendations – Alternating Least Squares
- Regression for Predictions – Logistic Regression, Lasso Regression, Ridge Regression, Linear Regression and Support Vector Machines (SVM).
- Clustering – Linear Discriminant Analysis, K-Mean and Gaussian,
- Classification Algorithms – Naïve Bayes, Ensemble Methods, and Decision Trees.
- Dimensionality Reduction –PCA (Principal Component Analysis) and Singular Value Decomposition (SVD)
Benefits of Spark MLib:
- Spark MLlib is tightly integrated on top of Spark which eases the development of efficient large-scale machine learning algorithms as are usually iterative in nature.
- MLlib is easy to deploy and does not require any pre-installation, if Hadoop 2 cluster is already installed and running.
- Spark MLlib’s scalability, simplicity, and language compatibility helps data scientists solve iterative data problems faster.
- MLlib provides ultimate performance gains (about 10 to 100 times faster than Hadoop and Apache Mahout).
Features of Spark MLlib Library:
- MLlib provides algorithmic optimisations for accurate predictions and efficient distributed learning.
- For instance, the alternating least squares machine learning algorithms for making recommendations effectively uses blocking to reduce JVM garbage collection overhead.
- MLlib benefits from its tight integration with various spark components.
- MLlib provides a package called spark.ml to simplify the development and performance tuning of multi-stage machine learning pipelines.
- MLlib provides high-level API’s which help data scientists swap out a standard learning approach instead of using their own specialized machine learning algorithms.
- MLlib provides fast and distributed implementations of common machine learning algorithms along with a number of low-level primitives and various utilities for statistical analysis, feature extraction, convex optimizations, and distributed linear algebra.
- Spark MLlib library has extensive documentation which describes all the supported utilities and methods with several spark machine learning example codes and the API docs for all the supported languages.
Spark Mlib Tools:
- Ml Algorithms: classfication, regrssion, clustering and collaborative filtering
- Featurization: feature extraction, transformation, dimensionality reduction, and selection
- Pipelines: tools for constructing, evaluating and tunnignML pipelines
- Persistence: saving and loading algorithms, models and pipelines
- Utilities: linear algebra, statistics, data handling

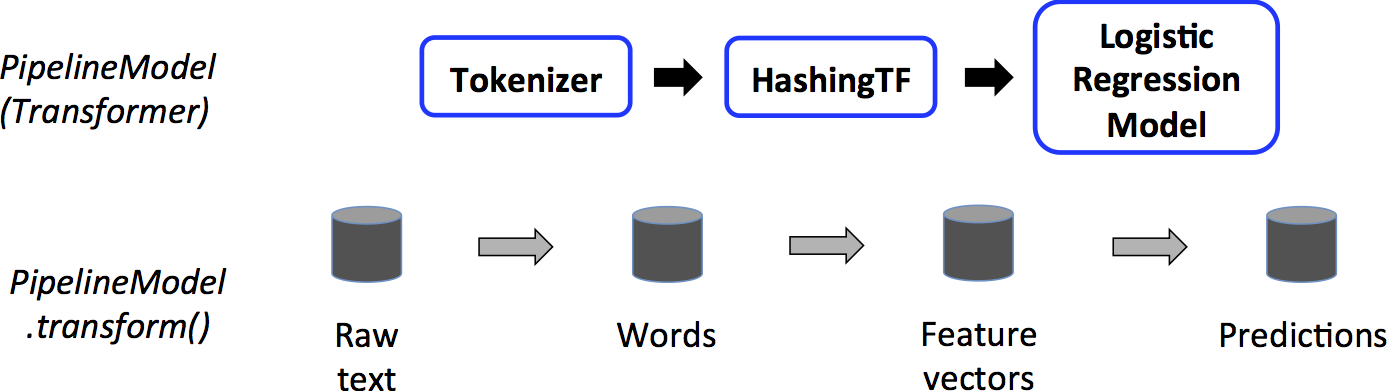
Machine learning Pipelines componenets:
- Data frame: The ML API uses Dataframe from Spark SQL as a dataset, which can be used to hold a variety of datatypes
- Transformer: This is used to transform one Dataframe to another Dataframe. Examples are
- Hashing Term Frequency: This calculates how word
occurs - Logistic Regression Model: The model which results
from trying logistic regressions on a dataset - Binarizer: This changes a given threshold value to 1
or 0
- Hashing Term Frequency: This calculates how word
- Estimator: It is an algorithm which can be used on a Dataframe to produce Transformer. Examples are:
- Logistic Regression: It is used to determine the weights for the resulting Logistic Regression Model by processing the dataframe
- Standard Scaler: It is used to calculate the Standard deviation
- Pipeline: Calling fit on a pipeline produces pipeline model, and the pipeline contains only transformers and not the estimators
- Pipeline: A pipeline chains multiple Transformers and Estimators together to specify the ML workflow
- Parameters: To specify the parameters a common API is used by the Transformers and Estimators
For more information about Hadoop and HDFS, Hive

One thought on “Introduction to Apache Spark, SparkQL, and Spark MLib.”