In this blog, we will focus on fault tolerance in distributed systems, two phase commit protocol and Voting Protocol. Also focus on recovery in distributed systems, backward and forward error recovery, database modification with state based approach and Checkpoint algorithm. Also a little information on Distributed database.
A.Fault Tolerance
Key approaches to design fault tolerant systems:
- Commit protocols(well defined failure).
- Voting protocols(mask failures).
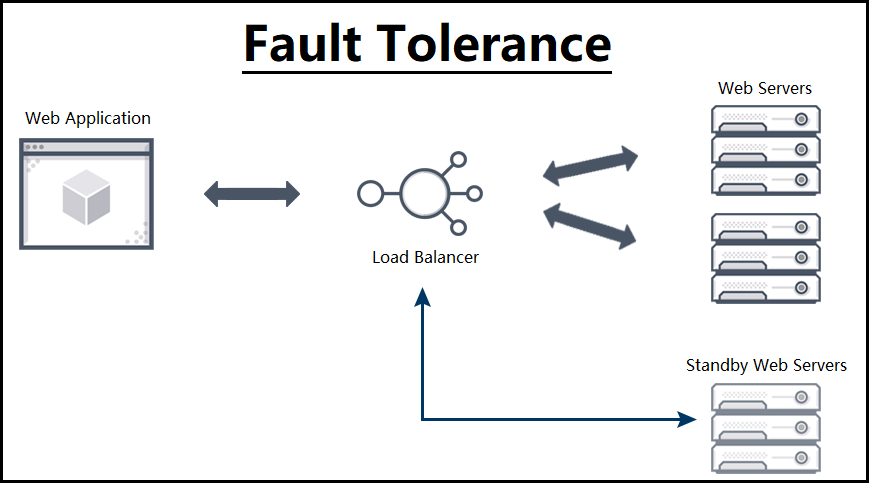
Atomic actions are basic building blocks in constructing fault tolerant operations, they have following characteristics:
- If the process performing is not aware of the existence of any other active processes and vice -a –versa
- If the process performing it does not communicate with other process while the action is being performed
- If the process performing it can detect no state changes except performed by itself, and if it does not reveal its state change until the action is complete
- If they can be considered to be individual and instantaneous
All the sites should either commit or abort sub-transactions of a transaction in commit protocol,
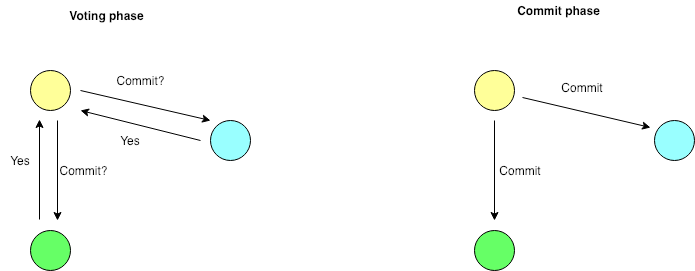
A.The two Phase commit protocol
One of the processes is the coordinator and other processes are cohorts.
Phase 1: Coordinator
- Coordinator sends a Commit_Request message to every cohort requesting the cohorts to commit.
- The coordinator waits for the replies.
Phase 1: Cohort
- On receipt of Commit request
- If the transaction is successful
- Writes undo and redo log on the stable storage.
- Sends Agreed message to the coordinator.
- Else if transaction is unsuccessful then
- It sends an ABORT message to the coordinator.
- If the transaction is successful
Phase 2 : Coordinator
- If all the cohorts reply agreed and the coordinator also agrees, then the coordinator writes a commit record in to the LOG. Otherwise it sends an ABORT message to all the cohorts.
- The coordinator waits for acks from each cohort.
- If an ack does not arrive from any cohort within time out period, the coordinator resend the commit/abort message to that cohort.
- If all the acknowledgements are received , the coordinator writes a COMPLETE record to the log.
Phase 2 : Cohorts
- On receiving a COMMIT message, a cohort releases all the resources and locks held by it for executing the transaction, and sends an acknowledgement.
- On receiving an ABORT message , undoes the transaction using the undo log record, releases all the resources and locks held by it for performing the transaction, and sends an acknowledgement.

What happens when Site failure happens?
- Suppose the coordinator crashes before having written the COMMIT record.
- On recovery- it broadcasts an ABORT msg. to all cohorts. Those who had agreed to commit will simply undo and others will abort the transaction
- After writing the COMMIT but before writing the COMPLETE record.
- On recovery- it broadcasts a COMMIT msg. to all cohorts and waits for acks.
- After writing the COMPLETE record.
- On recovery- there is nothing to be done for transaction.
- If the Cohorts crashes in Phase-I,
- On recovery- Coordinator can abort the transaction: not received reply
- If the Cohort crashes in Phase-II, i.e. after writing its UNDO and REDO log
- On recovery- the cohort will check with the coordinator whether to abort or to commit the transaction
While the two-phase commit protocol guarantees global atomic, its biggest drawback is that is a blocking protocol. Whenever the coordinator fails, cohort sites will have to wait for its recovery. This is undesirable as these sites may be holding locks on the resources. In the event of message loss, the two-phase protocol will result in the sending of more messages.
B.Voting Protocols:
With the voting mechanism, each replica is assigned some number of votes, and a majority of votes must be collected from a process before it can access a replica. The voting mechanism is more fault-tolerant than a commit protocol in that it allows access to data under network partitions, site failures and message losses without compromising the integrity of the data.
It allows access to the data under network partitions, site failures, and message losses without losing the integrity of data lock mechanism is used.
Every replica is assigned a certain number of votes. This information is store on stable storage. A read or write is permitted if a certain number of votes, read quorum or write quorum, respectively, are collected by the requesting process.
- Every replica is assigned a certain number of votes`
- Every site has a lock manager.
- Every file has a version number.
- Every replica is assigned a certain number of votes.
- Read and write permitted only if a certain number of votes are obtained(read quorum) and (Write quorum) by the requesting process.
B.Recovery of a System:
Failure of a system occurs when the system does not perform its services in the manner specified. Classification of faults,
- Process Failure(transaction failure)
- System Failure
- Secondary storage failure
- Communication Medium Failure
Backward and forward error recovery
An error is that part of the state that differs from its intended value and can lead to a system failure, and failure recovery is a process that involves restoring an erroneous state to an error free state.
- Forward error recovery: If the nature of errors and damages caused by faults can be completely and accurately assessed, then it is possible to remove those errors in the process’s state and enable the process to move forward.
- Backward error recovery: If it is not possible to foresee the nature of faults and to remove all the errors in the process’s state, then the process state can be restored to a previous error free state of the process.
Backward-error recovery is simpler than forwarding error recovery as it is independent of the fault and the errors caused by the fault. Thus, a system can recover from an arbitrary fault by restoring to a previous state. The major problems associated with the backward error,
- Performance penalty: The overhead to restore a process state to a prior state can be quite high
- There is no guarantee that faults will not occur again when processing begins from a prior state
- Some component of the system may be unrecoverable
The forward- error recovery technique on the other hand, incurs less overhead because only those parts of the state that deviate from the intended value need to be corrected.

Logs are used to store the records. Typically all write records need to be logged. There are two types,
- write(A) —> < Ti, A, old value, new_value>
- write(A) —> <Ti, A, new_value>
Database modification:
A.Immediate database Modification
- Write outputs to the database while the transaction is still active.
- Uncommitted modifications.
- In the event of a crash, we undo the uncommitted transactions.
- Log record: Write <Ti, X, old, new>to the log.
- Recovery procedures required are:
- undo(Ti): The old state of the object (used for UNDO)
- redo(Ti): The new state of the object (used for REDO)
Deferred database modification: Deferring the write operations of all the write operations of a transaction partially commits. Log record is typically <To, A, new_val> and Recovery procedure is Redo(Ti).
B.State based Approach:
Recovery Point/ Checkpoint: In the state-based approach or recovery, the complete state of a process is saved when a recovery point is established, and recovering a process involves reinstating its saved state and resuming the execution of the process from that state.
The recovery point at which check pointing occurs is often referred to as a checkpoint. The process of restoring a process to a prior state is referred to as rolling back the process.
Shadow Pages, where only a part of the system state is saved to facilitate recovery. Whenever a process wants to modify an object, the page containing the object is duplicated and is maintained on stable storage.
The complete state of a process is saved when a recovery point is established and recovering a process involves reinstating its saved state and resuming the execution of the process from that state.

Recovery in distributed system
In concurrent systems, several processes cooperate by exchanging information to accomplish a task. The information exchange can be through a shared memory in the case of shared memory machines or through messages in the case of a distributed.
To undo the effects caused by a failed process at an active process, the active process must also rollback to an earlier state. Thus, in concurrent systems, all cooperating processes need to establish recovery points. Rolling back processes in concurrent systems is more difficult than in the case of a single process.
Rolling back(UNDO) a process can cause further problems, such as Orphan messages, Domino effect, Live locks and Lost messages. Single failure can cause an infinite number of rollbacks, preventing the system to make any progress. The following procedure is followed,
- Processes exchange messages.
- If a process fails and resumes from a recovery point, then it also affects the other processes with which it interacts.
- Other processes also need to be undone.
1.Consistent set of checkpoints
- All the checkpoints were local checkpoints.
- All the local checkpoints, one from each site, collectively form a global checkpoint
- The problem was the information flow between two sites in the checkpoints.
- A recovery line or a strongly consistent set of checkpoints are required.
- No information flow in between the time interval i.e. no sending or receiving of messages in the interval.
- No orphan messages and no domino effect.
2.Synchronous check pointing and recovery
- Takes a consistent set of checkpoints and avoids live lock
- The processes coordinate their local check pointing actions.
- The checkpoints are globally consistent.
3.Checkpoint Algorithm
A.Assumptions:
- Channels are FIFO in nature.
- No message transfer during the check pointing process.
- Two stages in checkpoints:
- Temporary/tentative checkpoint
- Permanent checkpoint.
- Only a single process invokes the algorithm.
- No site fails during the algorithm.
B.Algorithm:
1.First Phase:
- An Initiating Process Pi takes a temporary checkpoint and requests all the processes to take tentative checkpoints.
- Each process informs Pi whether it succeeded in taking the checkpoint i.e. either YES/NO
- When Pi receives “YES” from all the processes, then converts the temporary checkpoints to permanent.
- If it receives “NO” from anyone site too, then all the tentative checkpoints are discarded.
2. Second Phase:
- Pi informs all the processes of the decision, it reached at the end of the first phase.
- A process, on receiving the message from Pi, will act accordingly.
- Thus all or none take permanent checkpoints.
We get a strongly consistent set of check points because,
- Either all or none of the processes take permanent checkpoints.
- No process sends messages after taking a temporary checkpoint until the receipt of the initiating process’s decision, by which time all processes would have taken the checkpoints.
C.Distributed Database?
Collections of data that are distributed across multiple physical locations connected over a network. The replication and distribution of databases improve database performance at worksites.
Check pointing in Distributed database
Check pointing scheme for DDBS should have 2 objectives:
- Normal operations are minimally interfered with by checkpoints
- For fast recovery, it is desirable that the checkpoints taken are consistent
- Consistency is a transaction–centric (not send & receive messages)
- All the updates of the transaction are made or none is made.
- Issue is:
- which transaction’s updates should be included in the database.
- Also how to take local check points in no interfering way.
Assumptions about the Check point algorithm in a DDBS:
- The basic unit of user activity is a transaction
- Transaction follow some concurrency control protocols
- Lamport’s logical clocks are used to associate a time stamp for each transaction.
- Site failures are detectable either by network protocol or by time out mechanism
- Network partitioning never occurs
Basic Idea:
- All the participating sites agree upon a special timestamp known as Global Checkpoint number (GCPN)
- The updates of the transaction which have timestamps ≤ GCPN are included in the checkpoints
- These checkpoints are called: before-checkpoint-transactions (BCPTs)
- The updates of the transaction which have timestamps > GCPN are not included in the checkpoints, these are called after–checkpoint-transactions (ACPTs)
- During check pointing ACPTs are active, BCPTs hold.
For more information,
- http://cse.csusb.edu/tongyu/courses/cs461/notes/index.php
- https://courses.cs.washington.edu/courses/cse452/
- https://www.cl.cam.ac.uk/teaching/2021/ConcDisSys/dist-sys-notes.pdf
For more information on the following topics,
- What do you mean by Distributed Systems, Shared Memory and File Systems: https://programmerprodigy.code.blog/2021/07/07/what-do-you-mean-by-distributed-systems-shared-memory-and-file-systems/
- How to synchronize distributed systems: https://programmerprodigy.code.blog/2021/07/07/how-to-synchronize-distributed-systems/
- How to detect a Deadlock and resolve it in Distributed Systems: https://programmerprodigy.code.blog/2021/07/07/how-to-detect-a-deadlock-and-resolve-it-in-distributed-systems/

{kind=link}
3 thoughts on “Fault Tolerance and Recovery in Distributed systems”