In this blog, we will focus on how to synchronize distributed systems( actual time, relative time, Based on mutual exclusion, Election algorithms and Transactions).
Synchronization are important to control access to a single shared resource by agreeing on the ordering of systems. We can Synchronize in distributed based on the following,
1.Based on Actual time:
When each machine has its own clock, an event that occurred after another event may nevertheless be assigned an earlier time.
With multiple computers, “clock skew” ensures that no two machines have the same value for the “current time”. Algorithms based on the current time have been devised for use within a Distributed System.
A. Cristian’s Algorithm: Getting the current time from a “time server”, using periodic client requests.
Major problem if time from time server is less than the client – resulting in time running backwards on the client! (Which cannot happen – time does not go backwards).
Minor problem results from the delay introduced by the network request/response: latency.
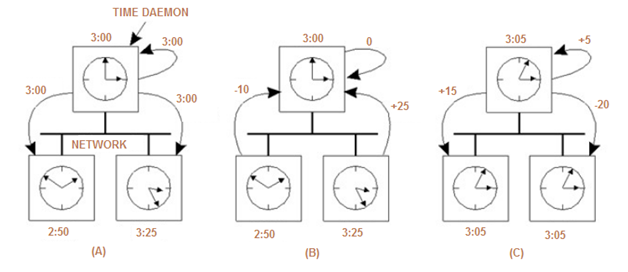
B. Berkeley Algorithm:
- The time daemon asks all the other machines for their clock values
- The machines answer
- The time daemon tells everyone how to adjust their clock
2.Based on Relative Time:
There is no requirement for “relative time” to have any relation to the “real time”. What’s important is that the processes in the Distributed System agree on the ordering in which certain events occur. Such “clocks” are referred to as Logical Clocks.
Lamport’s Logical Clocks rules?
- If two processes do not interact, then their clocks do not need to be synchronized – they can operate concurrently without fear of interfering with each other.
- It does not matter that two processes share a common notion of what the “real” current time is. What does matter is that the processes have some agreement on the order in which certain events occur.
Lamport used these two observations to define the “happens-before” relation. If A and B are events in the same process, and A occurs before B, then we can state that: A “happens-before” B is true. An example would be ,
- Now, assume three processes are in a DS: A, B and C.
- All have their own physical clocks (which are running at differing rates due to “clock skew”).
- A sends a message to B and includes a “timestamp”.
- If this sending timestamp is less than the time of arrival at B, things are OK, as the “happens-before” relation still holds (i.e., A “happens-before” B is true).
- However, if the timestamp is more than the time of arrival at B, things are NOT OK (as A “happens-before” B is not true, and this cannot be as the receipt of a message has to occur after it was sent).
How can some event that “happens-before” some other event possibly have occurred at a later time??
Lamport’s solution is to have the receiving process adjust its clock forward to one more than the sending timestamp value. This allows the “happens-before” relation to hold, and also keeps all the clocks running in a synchronized state. The clocks are all kept in sync relative to each other.
A.Lamport algorithm: Each process increments its clock counter between every two consecutive events.
If a sends a message to b, then the message must include T(a). Upon receiving a and T(a), the receiving process must set its clock to the greater of [T(a)+d, Current Clock]. That is, if the recipient’s clock is behind, it must be advanced to preserve the happen-before relationship. Usually d=1.
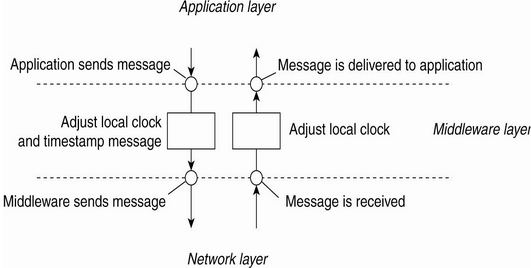
B.Totally-Ordered Multi casting?
Updating a replicated database and leaving it in an inconsistent state: Update 1 adds 100 euro to an account, Update 2 calculates and adds 1% interest to the same account. Due to network delays, the updates may not happen in the correct order. Whoops!
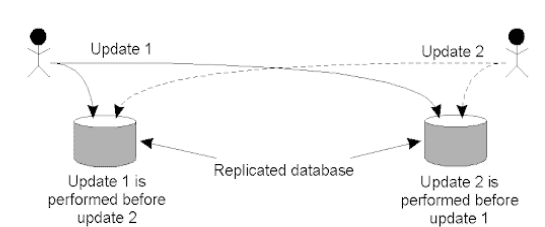
- Update 1 is time-stamped and multicast. Added to local queues.
- Update 2 is time-stamped and multicast. Added to local queues.
- Acknowledgements for Update 2 sent/received. Update 2 can now be processed.
- Acknowledgements for Update 1 sent/received. Update 1 can now be processed.
Totally-Ordered Multi casting Algorithm:
- A multicast message is sent to all processes in the group, including the sender, together with the sender’s timestamp.
- At each process, the received message is added to a local queue, ordered by timestamp.
- Upon receipt of a message, a multicast acknowledgement/timestamp is sent to the group.
- Due to the “happens-before” relationship holding, the timestamp of the acknowledgement is always greater than that of the original message.
- Only when a message is marked as acknowledged by all the other processes will it be removed from the queue and delivered to a waiting application.
- Lamport’s clocks ensure that each message has a unique timestamp, and consequently, the local queue at each process eventually contains the same contents.
- In this way, all messages are delivered/processed in the same order everywhere, and updates can occur in a consistent manner.
3. Based on Mutual Exclusion within Distributed Systems:
It is often necessary to protect a shared resource within a Distributed System using “mutual exclusion”. As, it might be necessary to ensure that no other process changes a shared resource while another process is working with it.
Requirements of Mutual exclusion Algorithm:
- No Deadlock: Two or more site should not endlessly wait for any message that will never arrive.
- No Starvation: Every site who wants to execute critical section should get an opportunity to execute it in finite time.
- Fairness: Each site should get a fair chance to execute critical section. Any request to execute critical section must be executed in the order they are made
- Fault Tolerance: In case of failure, it should be able to recognize it by itself in order to continue functioning without any disruption.
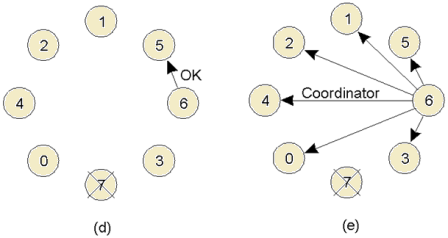
A.Centralized Algorithm:
- Process 1 asks the coordinator for permission to access a shared resource. Permission is granted.
- Process 2 then asks permission to access the same resource. The coordinator does not reply.
- When process 1 releases the resource, it tells the coordinator, which then replies to 2

Advantages,
- There’s no process starvation.
- Easy to implement.
Disadvantages,
- There’s a single point of failure!
- The coordinator is a bottleneck on busy systems.
If there is no reply, does this mean that the coordinator is “dead” or just busy?
B.Distributed Algorithms:
Below are the three approaches based on message passing,
1.Token Based Algorithm: Sequence Number is used to old/new request. As there’s only one token, so mutual exclusion is guaranteed. For example Suzuki Kasami algo
2.Non-token based approach: Time stamp instead of seq.no. logical clock is used.
Deadlock and starvation are not possibilities since the queue is maintained in order, and OKs are eventually sent to all processes with requests. For example Lamports and Ricart-Agrawala algo
3.Quorum based approach: Instead of requesting permission to execute the critical section from all other sites, Each site requests only a subset of sites which is called a quorum.
The algorithm works because in the case of a conflict, the lowest timestamp wins as everyone agrees on the total ordering of the events in the distributed system. For example Maekawa algo
None are perfect – they all have their problems!
- The “Centralized” algorithm is simple and efficient, but suffers from a single point-of-failure.
- The “Distributed” algorithm has nothing going for it – it is slow, complicated, inefficient of network bandwidth, and not very robust.
It “sucks”! - The “Token-Ring” algorithm suffers from the fact that it can sometimes take a long time to reenter a critical region having just exited it.

For more information on Algorithms,
- http://www.cs.fsu.edu/~xyuan/cop5611/lecture8.html
- https://people.cs.pitt.edu/~mosse/cs2510/class-notes/mutual-exclusion.pdf
- https://lsisreviving.weebly.com/uploads/2/3/6/8/23689241/ricart_agrawala.pdf
4.Based on Election Algorithms:
Many Distributed Systems require a process to act as coordinator. The selection of this process can be performed automatically by an “election algorithm”. For simplicity, we assume the following:
- Processes each have a unique, positive identifier.
- All processes know all other process identifiers.
- The process with the highest valued identifier is duly elected coordinator.
The overriding goal of all election algorithms is to have all the processes in a group agree on a coordinator. When an election “concludes”, a coordinator has been chosen and is known to all processes.
There are two types of election algorithm:
- Bully: “the biggest guy in town wins”.
- Ring: a logical, cyclic grouping.
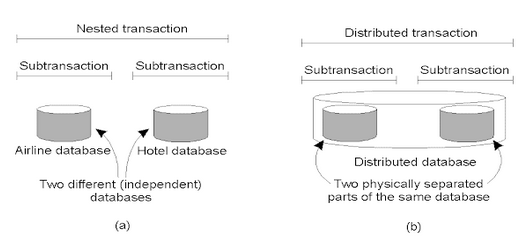
5. Based on Transactions:
- Transactions protect “shared data”.
- Often, a single transaction contains a collection of data accesses/modifications.
- The collection is treated as an “atomic operation”, either all the collection complete, or none of them do.
- Mechanisms exist for the system to revert to a previously “good state” whenever a transaction prematurely aborts.
Four key transaction characteristics,
- Atomic: the transaction is considered to be one thing, even though it may be made of up many different parts.
- Consistent: before the transaction must also hold after its successful execution.
- Isolated: if multiple transactions run at the same time, they must not interfere with each other.
- Durable: Once a transaction commits, any changes are permanent.
For more information,
- http://cse.csusb.edu/tongyu/courses/cs461/notes/index.php
- https://courses.cs.washington.edu/courses/cse452/
- https://www.cl.cam.ac.uk/teaching/2021/ConcDisSys/dist-sys-notes.pdf
For more information on the following topics,
- What do you mean by Distributed Systems, Shared Memory and File Systems: https://programmerprodigy.code.blog/2021/07/07/what-do-you-mean-by-distributed-systems-shared-memory-and-file-systems/
- How to detect a Deadlock and resolve it in Distributed Systems: https://programmerprodigy.code.blog/2021/07/07/how-to-detect-a-deadlock-and-resolve-it-in-distributed-systems/
- Fault Tolerance and Recovery in Distributed systems: https://programmerprodigy.code.blog/2021/07/07/fault-tolerance-and-recovery-in-distributed-systems/

great piece of content
LikeLike
It’s difficult to find well-informed people in this particular topic, however, you sound like you know what you’re talking about! Thanks
LikeLike
Spot on with this write-up, I actually suppose this web site needs much more consideration. I’ll in all probability be once more to learn far more, thanks for that info.
LikeLike