This blog focuses on operating system evolution and structures, process management with process scheduling algorithms, and process synchronization with semaphores and monitors.
What is an Operating System(OS)?
An OS is a program that acts as an interface between computer system users and the computer hardware. Every computer system must have at least one operating system to run other programs
Evolution of OS:
1.Serial Processing: The programs are submitted to the machine one after one, therefore the method is said to be serial processing.
2.Batch Processing: In batch processing technique, the same type of jobs batch together and execute at a time. A few point to note,
- Jobs, together with input data are fed into the system in a batch
- The jobs are then run one after another
- No job can be started until previous job is completed
3.Multiprogramming: In multiprogramming, a number of processes reside in the main memory at a time. The OS picks and begins to execute one of the jobs in the main memory. But in a multiprogramming environment, if any I/O wait happened in a process, then the CPU switches from that job to another job in the job pool. So, the CPU is not idle at any time.
Maintains synchronization between I/O devices & processes. Hence, CPU switches from one task to another for reading & processing. Thus idle time for peripherals gets reduced. Many jobs can be handled simultaneously.
The code and data of several processes is stored in main memory. Also, More programs run by user = More memory is required

4.Multi tasking: to handle or more programs at the same time from a single user’s perception. CPU can only perform one task at a time, however it runs so fast that 2 or more jobs seem to execute at the same time.
5.Time sharing: Multiple jobs are executed by the CPU switching between them. The CPU scheduler selects a job from the ready queue and switches the CPU to that job. When the time slot expires, the CPU switches from this job to another.
In this method, the CPU time is shared by different processes. So, it is said to be “Time-Sharing System“. Generally, time slots are defined by the operating system.
6.Parallel System: Also known as multiprocessor system, such system have more than one processor in close communication, sharing the computer bus, the clock, and sometimes memory and peripheral devices. In the parallel system, a number of processors are executing there job in parallel. Types of Multi processors,
1.Asymmetric multi processor OS: A specific task is assigned to each processor.
- Master & Many slaves
- Master – controls the system
- Slaves – follows instructions of master or perform their predefined task.
2.Symmetric multiprocessor OS: They perform all tasks within OS
- No master slave concept used.
- All the processors are peer processors.
- Many processes can run simultaneously.
Advantages:
- No. of processors, more work is done in short period of time.
- Failure of one processor will not halt the system, but it will slow it down.
- Large main memory is required.
Operating System Structures:
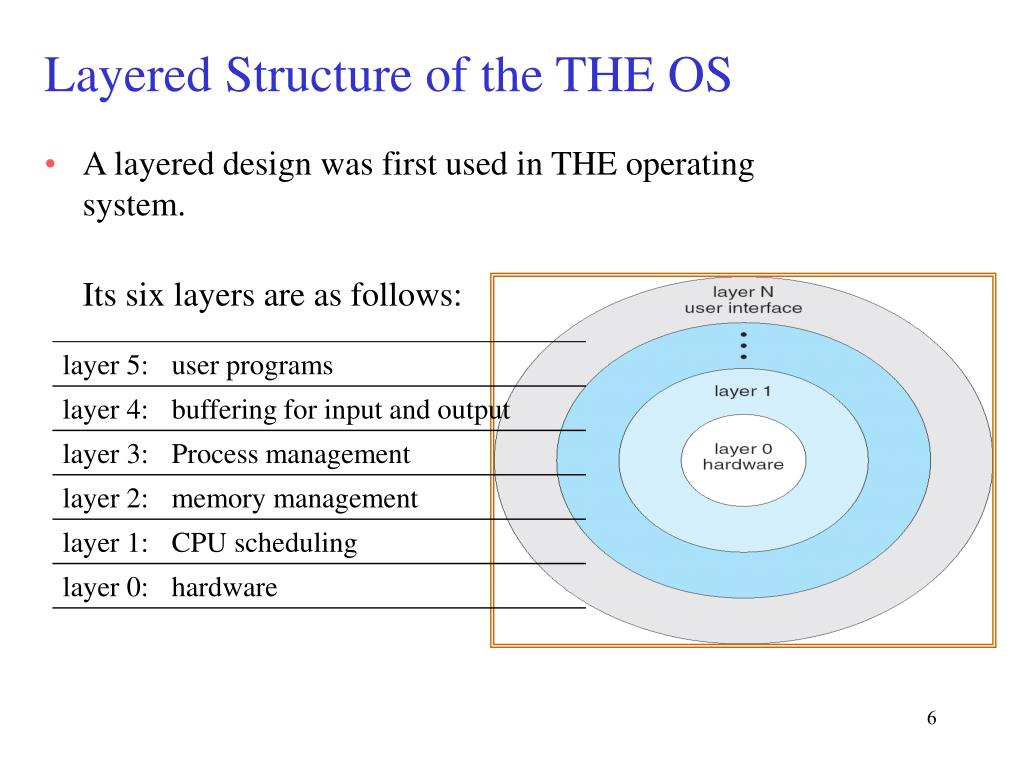
1.Layered OS:
- Hardware: This layer interacts with the system hardware and coordinates with all the peripheral devices used such as printer, mouse, keyboard, scanner etc.
- CPU Scheduling: This layer deals with scheduling the processes for the CPU. There are many scheduling queues that are used to handle processes. When the processes enter the system, they are put into the job queue. The processes that are ready to execute in the main memory are kept in the ready queue.
- Memory Management: Memory management deals with memory and the moving of processes from disk to primary memory for execution and back again. This is handled by the third layer of the operating system.
- Process Management: This layer is responsible for managing the processes i.e assigning the processor to a process at a time. This is known as process scheduling. The different algorithms used for process scheduling are FCFS (first come first served), SJF (shortest job first), priority scheduling, round-robin scheduling, etc.
- I/O Buffer: I/O devices are very important in computer systems. They provide users with the means of interacting with the system. This layer handles the buffers for the I/O devices and makes sure that they work correctly.
- User Programs: This is the highest layer in the layered operating system. This layer deals with the many user programs and applications that run in an operating system such as word processors, games, browsers, etc.
Advantages of layered architecture:
- Dysfunction of one layer will not affect the entire OS
- Easier testing and debugging due to isolation among the layers
- Adding new functionalities or removing the obsolete ones is very easy
Disadvantages of layered architecture
- It is not always possible to divide the functionalities, many a times they are inter related and can’t be separated.
- Sometimes, a large no of functionalities is there and number of layers increase greatly. This might lead to degradation in performance of the system
- No communication between non adjacent layers
2.Micro kernel Architecture
Kernel is the core part of the operating system which manages system resources. It also acts like a bridge between application and hardware of the computer.
As it is meant for handling the most important services only. Thus in this architecture only the most important services are inside kernel and rest of the OS services are present inside system application program. Thus users are able to interact with those not-so important services within the system application. And the micro kernel is solely responsible for the most important services of operating system they are named as follows:
- Inter process-Communication
- Memory Management
- CPU-Scheduling
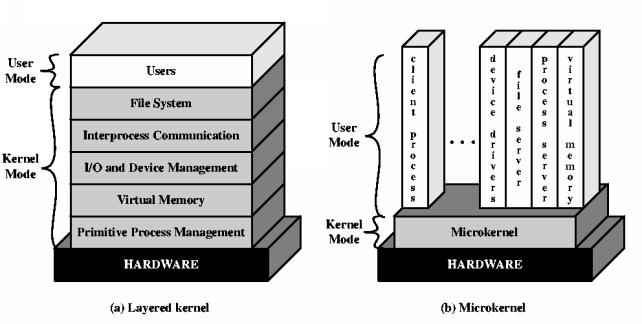
3.Micro kernel System Structure
Moves as much from the kernel into “user” space. Communication takes place between user modules using message passing
Advantages:
- Easier to extend the system as it is simply added in the system application without disturbing the kernel
- Architecture is small and isolated and hence functions efficiently
- More reliable and more secure
Disadvantages:
- Performance overhead of user space to kernel space communication
4.Monolithic approach:
The entire operating system works in the kernel space in the monolithic system. This increases the size of the kernel as well as the operating system. This is different than the microkernel system where the minimum software that is required to correctly implement an operating system is kept in the kernel.
The kernel provides various services such as memory management, file management, process scheduling etc. using function calls. This makes the execution of the operating system quite fast as the services are implemented under the same address space.
Advantages :
- The execution of the monolithic kernel is quite fast as the services such as memory management, file management, process scheduling etc. are implemented under the same address space.
- A process runs completely in a single address space in the monolithic kernel.
Disadvantages:
- If any service fails in the monolithic kernel, it leads to the failure of the entire system.
- To add any new service, the entire operating system needs to be modified by the user.
Process management:
Process is a program in execution. Process execution must progress in sequential fashion.
- Logically : each process has its separate virtual CPU.
- Real : CPU switches from one process to another.
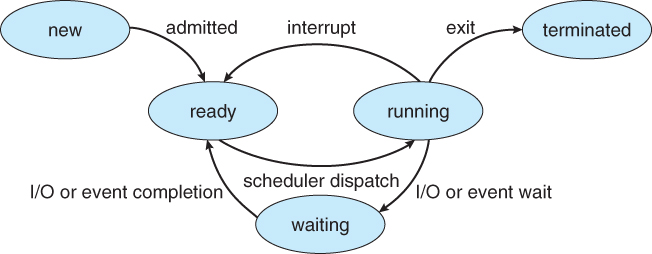
As a process executes, it changes state
- new: The process is being created
- running: Instructions are being executed
- waiting: The process is waiting for some event to occur
- ready: The process is waiting to be assigned to a processor
- terminated: The process has finished execution
Process Control Block (PCB): Information associated with each process such as process state, program counter, CPU registers, CPU scheduling information, memory management information, accounting information, and I/O status information.
Maximum CPU utilization is obtained with multi programming
- Several processes are kept in memory at one time
- Every time a running process has to wait, another process can take over use of the CPU
Process execution consists of a cycle of a CPU time burst or CPU execution and an I/O time burst (i.e. wait).
- Processes alternate between these two states (i.e., CPU burst and I/O burst)
- Eventually, the final CPU burst ends with a system request to terminate the execution
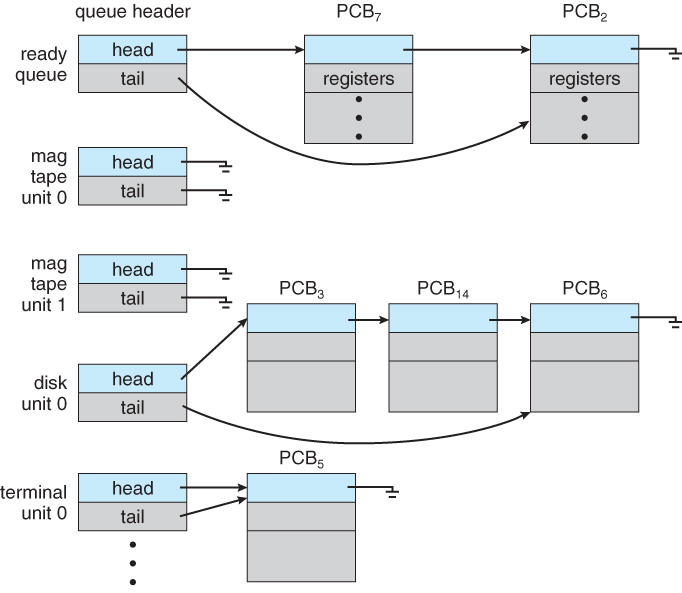
Process Scheduling Queues
- Job queue – set of all processes in the system
- Ready queue – set of all processes residing in main memory, ready and waiting to execute
- Device queues – set of processes waiting for an I/O device
- Processes migrate among the various queues
SINGLE PROCESSOR SCHEDULING ALGORITHMS:
Different CPU scheduling algorithms have different properties and may favor one class of processes over another. In choosing which algorithm to use in a particular situation, the properties of various algorithms must be considered.
Some of the criteria suggested for comparing CPU scheduling algorithms are:
- CPU utilization – The main objective of any CPU scheduling algorithm is to keep the CPU as busy as possible.
- Throughput – A measure of the work done by the CPU is the number of processes being executed and completed per unit time. The throughput may vary depending upon the length or duration of the processes.
- Turnaround time – For a particular process, Turn-around time is the sum of times spent waiting to get into memory, waiting in the ready queue, executing in CPU, and waiting for I/O.
- Waiting time – A scheduling algorithm does not affect the time required to complete the process once it starts execution.
- Response time – A process may produce some output fairly early and continue computing new results while previous results are being output to the user. The time taken from submission of the process of the request until the first response is produced.
Some of the Single Processor scheduling algorithms,
1.FIRST COME, FIRST SERVED (FCFS) SCHEDULING:
The FCFS scheduling algorithm is non-preemptive. Once the CPU has been allocated to a process, that process keeps the CPU until it releases it either by terminating or by requesting I/O. It is a troublesome algorithm for time-sharing systems
2.SHORTEST JOB FIRST (SJF) SCHEDULING :
The SJF algorithm associates with each process the length of its next CPU burst. When the CPU becomes available, it is assigned to the process that has the smallest next CPU burst. If two processes have the same length next CPU Burst then the FCFS scheduling algorithm is used to select the next process.
Advantages:
- Overall performance is slightly improved in terms of response time
- It’s having the least average waiting time, average turn around time and average response time
Disadvantages:
- There is a risk of starvation of longer processes
- It is difficult to know the length of the next CPU burst time
3.PRIORITY SCHEDULING:
The SJF algorithm is a special case of the general priority scheduling algorithm. The CPU is allocated to the process with the highest priority.
SJF is a priority scheduling algorithm where priority is the predicted next CPU burst time
The main problem with priority scheduling is starvation, that is, low priority processes may never execute. A solution is aging; as time progresses, the priority of a process in the ready queue is increased.

4.ROUND ROBIN (RR) SCHEDULING:
In the Round Robin concept, the algorithm uses time-sharing. Each process gets CPU time called a quantum time to limit the processing time. After time runs out, the process is delayed and added to the ready queue.
If there are n processes in the ready queue and the time quantum q, then each process gets 1/n of the CPU time at most q time units at once CPU scheduling. No process waits for more than (n-1) q time units.
5.MULTI-LEVEL QUEUE SCHEDULING
Multiple-level queues are not an independent scheduling algorithm. They make use of other existing algorithms to group and schedule jobs with common characteristics. Multi-level queue scheduling is used when processes can be classified.
- Multiple queues are maintained for processes with common characteristics.
- Each queue can have its own scheduling algorithms.
- Priorities are assigned to each queue.
In multi-level feedback queue scheduling, a process can move between the various queues; aging can be implemented this way
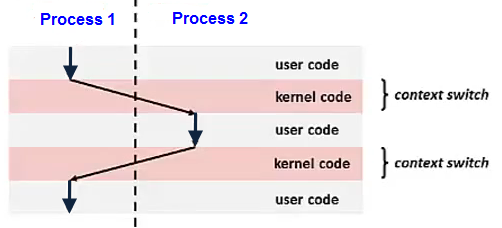
Context switch?
When the CPU switches to another process, the system must save the state of the old process and load the saved state for the new process. Context-switch time is overhead; the system does no useful work while switching.
Processes are the means of running programs to perform tasks. All required processes are not created when the computer gets started, as users start using a computer they go on assigning new tasks which then get converted into processes.
Parent processes create children processes, which, in turn, create other processes, forming a tree of processes. Generally, process identified and managed via a process identifier (pid).
Process Synchronization:
When multiple processes are accessing shared data without access control the final result depends on the execution order creating what we call race conditions.
- A serious problem for any concurrent system using shared variables
- We need access control using code sections that are executed atomically
Concurrent access to shared data may result in data inconsistency (e.g., due to race conditions). Maintaining data consistency requires mechanisms to ensure the orderly execution of cooperating processes.
Coordinate processes all competing to access shared data. Each process has a code segment called the critical section in which the shared data is accessed. The critical section should be short and with bounded waiting. The solution to the critical section problem.
Semaphores?
A semaphore is a higher-level mechanism for controlling concurrent access to shared resources. Instead of using operations to read and write a shared variable, a semaphore encapsulates the necessary shared data and allows access only by a restricted set of operations. The two 2 atomic operations that can modify semaphore are,
- Wait(): a process performs a wait operation to tell the semaphore that it wants exclusive access to the shared resource.
- Signal(): a process that performs a signal operation to inform the semaphore that it is finished using the shared resource. If there are processes suspended on the semaphore, the semaphore wakes one of them up.

- If the semaphore is empty, then the semaphore enters the full state and allows the process to continue its execution immediately.
- If the semaphore is full, then the semaphore suspends the process (and remembers that the process is suspended).
- If there are no processes suspended on the semaphore, the semaphore goes into the empty state
A.Counting semaphore: Integer value can range over an unrestricted domain. Useful for k-exclusion scenarios of replicated resources
B.Binary semaphore: Integer value ranges only between 0 and 1. It can be simpler to implement. Also known as mutex locks.
Semaphores can be implemented in two ways:
- With busy waiting
- Without busy waiting
Must guarantee that no two processes can execute wait () and signal () on the same semaphore at the same time. With each semaphore there is an associated waiting queue.
Each entry in a waiting queue has two data items:
- Value
- Pointer to next record in the list
Two operations:
- block – place the process invoking the wait operation on the appropriate waiting queue.
- wakeup – remove one of processes in the waiting queue and place it in the ready queue
Problem with Semaphores:
- They are essentially shared global variables.
- There is no linguistic connection between the semaphore and the data to which the semaphore controls access.
- Access to semaphores can come from anywhere in a program.
- There is no control or guarantee of proper usage.
- Correct use of semaphore operations is important:
- signal (mutex) …. wait (mutex)
- Can violate mutual exclusion
- wait (mutex) … wait (mutex)
- Can lead to deadlock!
- Omitting of wait (mutex) or signal (mutex)
- signal (mutex) …. wait (mutex)

Monitor:
A monitor is a programming language construct that controls access to shared data. Synchronization code added by compiler enforced at runtime. A monitor is a module that encapsulates,
- Shared data structures
- Procedures that operate on shared data structures
- Synchronization between concurrent procedure invocations
A monitor protects its data from unstructured access. It guarantees that threads accessing its data through its procedures interact only in legitimate ways
A monitor has four components as shown below:
- The initialization component contains the code that is used exactly once when the monitor is created,
- The private data section contains all private data, including private procedures, that can only be used within the monitor. Thus, these private items are not visible from outside of the monitor.
- The monitor procedures are procedures that can be called from outside of the monitor.
- The monitor entry queue contains all threads that called monitor procedures but have not been granted permissions. Monitors are supposed to be used in a multithreaded or multi process environment in which multiple threads/processes may call the monitor procedures at the same time asking for service.
- Thus, a monitor guarantees that at any moment at most one thread can be executing in a monitor!
For more information on Operating systems,
- https://www.cs.uic.edu/~jbell/CourseNotes/OperatingSystems/
- cis2.oc.ctc.edu/oc_apps/Westlund/xbook/xbook.php?unit=01&proc=book
To know how does OS manage memory and virtual memory, refer https://programmerprodigy.code.blog/2021/07/14/how-does-os-manage-memory-and-virtual-memory/
