In this blog, we will focus on how to prevent a deadlock, how to detect a deadlock, centralized, decentralized and hierarchical resolution algorithms for deadlock.
A set of processes is said to be in a deadlock when every process in the set waits for an event that can only be caused by another process in the set.
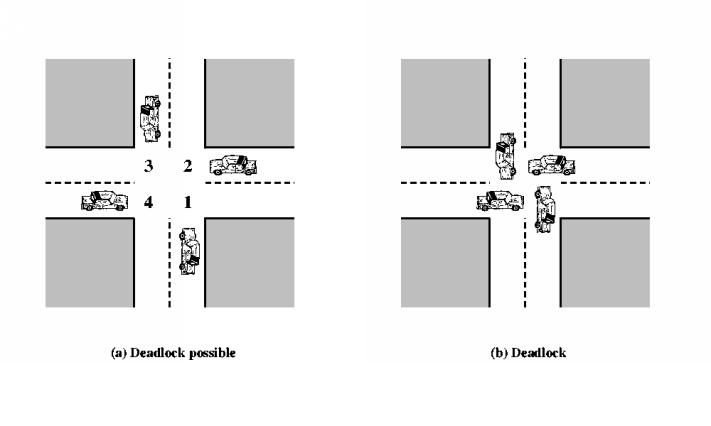
Deadlock can arise if four conditions hold simultaneously,
- Mutual exclusion: only one process at a time can use a resource. ( Resources : not in shared mode )
- Hold and wait: a process holding resource(s) is waiting to acquire additional resources held by other processes.
- No preemption: a resource can be released only voluntarily by the process holding it upon its task completion.
- Circular wait: there exists a set {P0, P1, …, P0} of waiting processes such that P0 is waiting for a resource that is held by P1, P1 is waiting for a resource that is held by P2, …, Pn–1 is waiting for a resource that is held by Pn, and Pn is waiting for a resource that is held by P0.
System Model for deadlock detection?
A.Resource Allocation Graph: It represents Process Resource interaction in distributed system. If cycle or knot present in resource allocation graph system is in deadlock. Resource-Allocation Graphs have the following properties
- A set of resource categories, { R1, R2, R3, . . ., RN }
- A set of processes, { P1, P2, P3, . . ., PN }
If all resources have only a single instance then we can define a deadlock detection algorithm that uses a variant of resource-allocation graph, called a wait for graph.
B.Wait For Graphs(WFG) : It represents system state (Same Graph without Resources). If cycle or knot present in WFG system is in deadlock.

Two types of Deadlocks,
1.Resource deadlock: uses AND condition.
AND condition: a process that requires resources for execution can proceed when it has acquired all those resources.
2.Communication deadlock: uses OR condition.
OR condition: a process that requires resources for execution can proceed when it has acquired at least one of those resources.
Deadlock conditions?
The condition for deadlock in a system using the AND condition is the existence of a cycle.A cycle is sufficient to declare a deadlock with this model.
The condition for deadlock in a system using the OR condition is the existence of a knot.
Knot: Subset of a graph such that starting from any node in the subset, it is impossible to leave the knot by following the edges of the graph.
Deadlock Handling Strategies
A.Deadlock Prevention:
We can prevent Deadlock by eliminating any of the four necessary conditions :
1.Eliminate Mutual Exclusion :
- Resources are sharable and non sharable.
- Sharable resources(files) do not require mutually exclusive access, so not involved in deadlock.
- Problem is with non sharable resources (TD, printer) ,they require ME access.
2.Eliminate Hold and Wait:
In order to ensure hold and wait condition never holds in the system : 2 Protocols can be used
- Allocate all required resources to the process before start of its execution, this way hold and wait condition is eliminated but it will lead to low device utilization.
- Requesting resources only when it has none. Process will make new request for resources after releasing the current set of resources.
Drawback : Starvation as process might have to wait for the resource indefinitely as the resource it requires is always allocated to some other process.
3.Eliminate No Preemption:
There is no pre-emption of resources that have already been allocated.
- Forcing a process waiting for a resource that cannot immediately, be allocated to release all of its currently held resources, so that other processes may use them to finish.
- When a resource is requested and not available, then the system looks to see what other processes currently have those resources and are themselves blocked waiting for some other resource. If such a process is found, then some of their resources may get preempted and added to the list of resources for which the process is waiting.
4.Eliminate Circular Wait :
Each resource will be assigned with a numerical number. A process can request for the resources only in increasing order of numbering.
The problem with this strategy is that it may be impossible to find an ordering that satisfies everyone.
B.Deadlock Avoidance :
In this approach, resource is allocated to the process if the resulting global system state is in safe state.
- Global state includes all processes and resources of DS.
- Safe state : if the system can allocate all resources requested by all processes without entering a deadlock state.
Because of the following problems, deadlock avoidance is impractical in DS
- Every site maintains a global state of the system huge storage requirements and extensive communication costs.
- Due to the large no. of processes and resources, it becomes expensive to check for a safe state.
C.Deadlock Detection :
Here we need to examine process resource allocation graph (RAG) to find cycles. DD in DS has 2 conditions :
- Once a cycle is formed in WFG, it persists until it is detected and broken
- Cycle detection can proceed concurrently with normal system activities.
A correct deadlock detection algo must,
1.Leave no undetected deadlocks.
- The algorithm must detect all existing deadlocks in finite time.
- Once a deadlock has occurred, the deadlock detection activity should continuously progress until the deadlock is detected.
2. Give no False Deadlocks
- The algorithm should not report deadlocks which are non existent( phantom deadlocks).
- In DS, no global memory, communication occurs by msg passing : difficult to design correct DD algo. coz site may obtain out of date and inconsistent WFG.
- As a result site may detect a cycle that doesn’t exist.
Resolution For deadlock detection?
Involves breaking existing wait for dependencies in the system WFG to resolve the deadlock.
Involves rolling back one or more processes that are deadlocked and assigning their resources to blocked processes in the deadlock so that they can resume execution.
A.Centralized Control
The centralized algorithm attempts to imitate the nondistributed algorithm by using a centralized coordinator. Each machine is responsible for maintaining its own processes and resources.
The coordinator maintains the resource utilization graph for the entire system. To accomplish this, the individual subgraphs need to be propagated to the coordinator. This can be done by sending a message each time an arc is added or deleted.
- One designated site (control site) has the responsibility of constructing a global WFG and searches for cycles.
- All decisions are made by the central control site.
- It must maintain the global WFG constantly
if the coordinator suspects deadlock, it can send a reliable message to every machine asking whether it has any release messages. Each machine will then respond with either a release message or a message indicating that it is not releasing any resources.
1.Ho Ramamoorthy Algorithm: 2 phase centralized deadlock detection algorithms :
Ho-Ramamoorthy 1-phase Algorithm
- Each site maintains 2 status tables: resource status table and process status table.
- Resource table: transactions that have locked or are waiting for resources.
- Process table: resources locked by or waited on by transactions.
- Controller periodically collects these tables from each site.
- Constructs a WFG from transactions common to both the tables.
- No cycle, no deadlocks.
Ho-Ramamurthy 2-phase Algorithm
- Each site maintains a status table of all processes initiated at that site: includes all resources locked & all resources being waited on.
- Controller requests (periodically) the status table from each site.
- Controller then constructs WFG from these tables, searches for cycle(s).
- If no cycles, no deadlocks.
- Otherwise, (cycle exists): Request for state tables again.
- Construct WFG based only on common transactions in the 2 tables.
- If the same cycle is detected again, system is in deadlock.
- Later proved: cycles in 2 consecutive reports need not result in a deadlock. Hence, this algorithm detects false deadlocks.
B.Distributed Algorithms
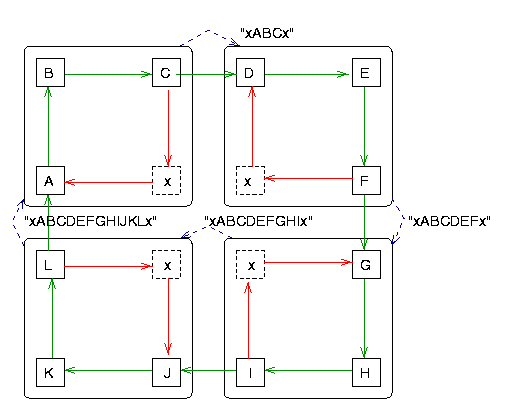
1.Path-pushing: resource dependency information disseminated through designated paths (in the graph). For Example,
A.Obermarck Algorithm:
Sites that detect a cycle in their partial WFG views convey the paths discovered to members of the (totally ordered) transaction. An algorithm can detect phantoms due to its asynchronous snapshot method.
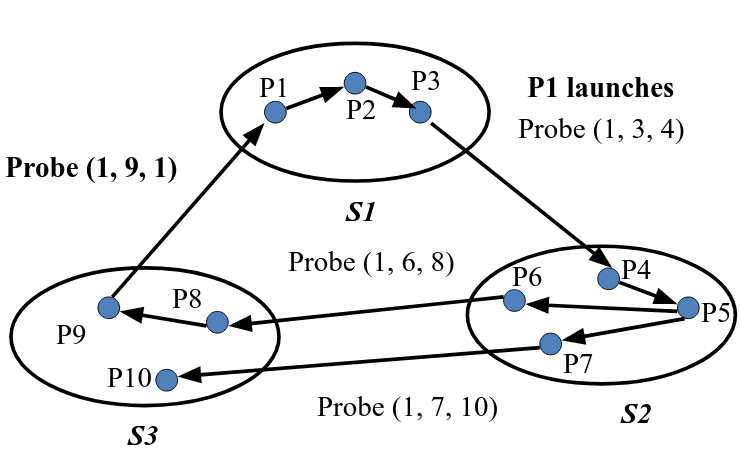
2.Edge-chasing: special messages or probes circulated along edges of WFG. Deadlock exists if the probe is received back by the initiator. For Example,
Chandy-Misra-Haas’s Algorithm (AND MODEL):
A probe(i, j, k) is used by a deadlock detection process Pi. This probe is sent by the home site of Pj to Pk. This probe message is circulated via the edges of the graph. Probe returning to Pi implies deadlock detection. Terms used are,
- Pj is dependent on Pk, if a sequence of Pj, Pi1,.., Pim, Pk exists.
- Pj is locally dependent on Pk, if above condition + Pj,Pk on same site.
Each process maintains an array dependent: dependent(j) is true if Pi knows that Pj is dependent on it. (initially set to false for all i & j).
3.Diffusion computation: queries on status sent to process in WFG. For Example,
Chandy-Misra-Haas’s Algorithm (OR MODEL):
Deadlock detection computations are diffused through the WFG of the system
- Query Message (i,j,k)
- Reply Message (i,j,k)
- Dependent set(process is waiting to receive a message)
The Algorithm is,
- Query message are sent from a computation (process or thread) on a node and diffused across the edges of the WFG
- When a query reaches an active (non-blocked) computation the query is discarded, but when a query reaches a blocked computation the query is echoed back to the originator when( and if) all outstanding => of the blocked computation are returned to it
- If all => sent are echoed back to an initiator, there is deadlock
- A waiting computation on node x periodically sends => to all computations it is waiting for (the dependent set), marked with the originator ID and target ID
- Each of these computations in turn will query their dependent set members (only if they are blocked themselves) marking each query with the originator ID, their own ID and a new target ID they are waiting on
- Computation cannot echo a reply to its requestor until it has received replies from its entire dependent set, at which time its sends a reply marked with the originator ID, its own ID and the most distant dependent ID
- When (and if) the original requestor receives echo replies from all members of its dependent set, it can declare a deadlock when an echo reply’s originator ID and most distant ID are its own

C.Hierarchical Deadlock Detection Algo:
It is somewhat similar to Ho-Ramamoorthy Algo :
- Sites are grouped into disjoint clusters.
- Periodically, a site is chosen as a central control site.
- Central control site chooses dynamically control site for each cluster.
- Control site collects status tables from its cluster, and uses the Ho-Ramamoorthy 1 Phase centralized deadlock detection algo to detect deadlock in that cluster.
- Central control site requests status tables from every control site.
- As a result, all control sites forward status info & its WFG to central control site.
- Central control site combines the info into a global WFG & searches it for cycles.
- Control sites detect deadlock in clusters.
- Central control site detects deadlock between clusters.

Follows Ho-Ramamoorthy’s 1-phase algorithm. More than 1 control site organized in hierarchical manner.
- Each control site applies 1-phase algorithm to detect (intracluster) deadlocks.
- The central site collects info from control sites, applies 1-phase algorithm to detect intercluster deadlocks
Deadlock persistence?
Average time a deadlock exists before it is resolved.
- The implication of persistence:
- Resources unavailable for this period: affects utilization
- Processes wait for this period unproductively: affects response time.
- Deadlock resolution:
- Aborting at least one process/request involved in the deadlock.
- Efficient resolution of deadlock requires knowledge of all processes and resources.
- If every process detects a deadlock and tries to resolve it independently -> highly inefficient! Several processes might be aborted.
Priorities for processes/transactions can be useful for resolution,
- Consider priorities introduced in Obermarck’s algorithm (path pushing)
- Highest priority process initiates and detects deadlock (initiations by lower priority ones are suppressed).
- When deadlock is detected, lowest priority process(es) can be aborted to resolve the deadlock.
- After identifying the processes/requests to be aborted,
- All resources held by the victims must be released. State of released resources restored to previous states. Released resources granted to deadlocked processes.
- All deadlock detection information concerning the victims must be removed at all the sites.
For more information,
- http://cse.csusb.edu/tongyu/courses/cs461/notes/index.php
- https://courses.cs.washington.edu/courses/cse452/
- https://www.cl.cam.ac.uk/teaching/2021/ConcDisSys/dist-sys-notes.pdf
For more information on the following topics,
- What do you mean by Distributed Systems, Shared Memory and File Systems: https://programmerprodigy.code.blog/2021/07/07/what-do-you-mean-by-distributed-systems-shared-memory-and-file-systems/
- How to synchronize distributed systems: https://programmerprodigy.code.blog/2021/07/07/how-to-synchronize-distributed-systems/
- Fault Tolerance and Recovery in Distributed systems: https://programmerprodigy.code.blog/2021/07/07/fault-tolerance-and-recovery-in-distributed-systems/

3 thoughts on “How to detect a Deadlock and resolve it in Distributed Systems?”