Hello, this blog contains the basic concepts and applications of array, vector, linked list, stack, queue, priority queue, binary tree, binary search tree, heaps, threaded binary tree, graphs and hash tables.
At the end it contains link to a GitHub repository, along with my another blog on different approaches to algorithms.
Data Structure is a way of collecting and organizing data ,such that we can optimize our code .

A real life example of data structure might be , your grocery list ,there are various ways you might write stuff on your list:
- Random groceries coming to your mind.
- Groceries based on priority levels .
- Groceries based alphabetically .
Various classification of Data Structures:

Memory :
There are two mechanism for storing data on your computer:
- Memory (RAM) – volatile memory
- Storage (ROM) – non volatile memory

- Stack: it’s where some of your processor’s information gets saved , for ex : functions ,variables , etc .This memory is managed by program. It works on LIFO principle .
- Heap: Used to allocate big data of memory ,this is what we call Dynamic Memory .This memory is managed by programmer .
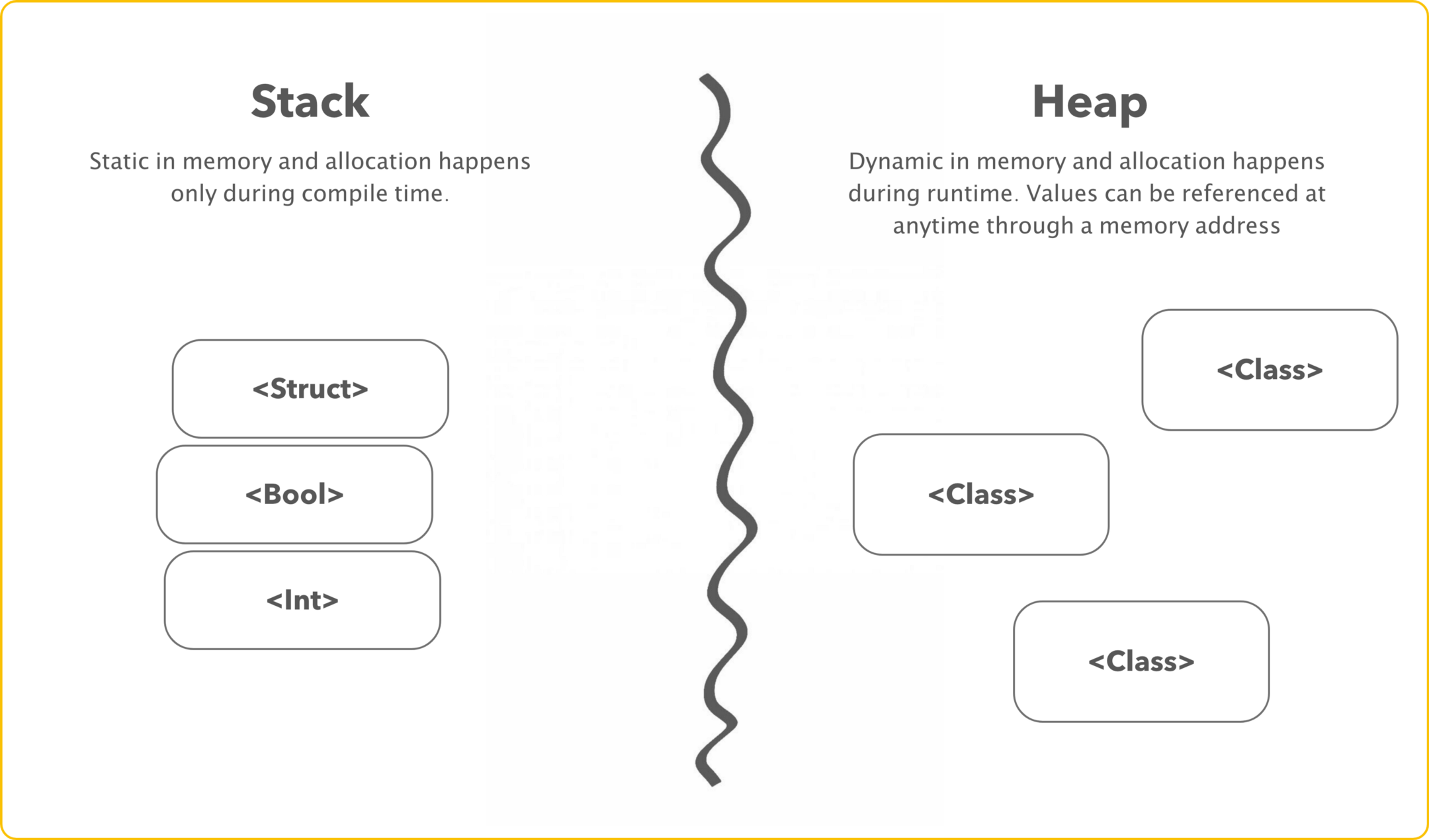
Q.How are variables stored in memory ?
You can think ram as a box ,divided into smaller cells ,each cell holds equal data . When you store data in a variable it gets converted into byte's , and each byte =8 bits , each block can hold 4 bits . For example : When you write int a =2 , a gets stored with binary value of 2 =0000 0010 , first four bits are stored in one cell and other four bits in next adjacent cell.
1.Array:
It is a collection of same data types stored in a data structure of fixed size.
Memory is allocated immediately after the array is created and it’s empty until you assign the values. Their elements are located in contiguous locations in memory,

int a[10] //declares an array of size 10 .
a[position_you_want_to_access] can be used to access a particular location of an array.
Applications of arrays:
- Many databases, small and large, consist of one-dimensional arrays whose elements are records.
- Arrays are used to implement other data structures, such as lists, heaps, hash tables, queues and stacks.
- CPU scheduling algorithms use implemented using arrays.
- All sorting algorithms use arrays at its core.
2.Vector:
It’s an array with dynamically allocated space, every time you exceed this space new place in memory is allocated and old array is copied to the new one. Old one is freed then.
When you define the size of the vector, for example 5. Now, when the array is full and you try to add a new element, the vector will double it’s size and allocate a new memory of size 10. You can further optimize it, so vector will be 1 1/2 of it’s size. In case of array, it would cause an error.
vector<int> v = { 7, 5, 16, 8 };
// Adding an integer to vector
v.push_back(25);
// Set element 1
data.at(1) = 88;
// There are various methods vectors such as begin(), ..
You can add new data to the end and to the front of the vector. Because Vector’s are array-like, then every time you want to add element to the beginning of the vector all the array has to be copied. Adding elements to the end of vector is far more efficient. There’s no such an issue with linked lists.
Vector gives random access to it’s internal kept data, while lists,queues,stacks do not.
3.Linked List:
A linked list may be defined if all the block are linked to each other ,using address of the blocks . It’s different from an array , as an array is a collection of simultaneous boxes , where as list is collection of boxes which are connected by a string .
An Example of Linked list ,will be people pointing to the next person in a line ,where the last person is not pointing to anyone.
Sequential Representation :
Then it’s physical data structure might look like :

Linked list will look like :

There are 3 types of Linked List:
- Single Linked list: Linked list which contains address of it’s next node only.
- Doubly linked List: Linked list which also contains address of it’s previous node , So we can iterate to both side while iterating. When we reverse a Link list it takes a lot of computational power.
- Circular Linked list: Has the next of last node pointing towards the first node of the list. This forms a circle of nodes as now last node and first node is connected , just like a circle.

Applications of Linked List :
- Linked Lists can be used to implement Stacks , Queues.
- Linked Lists can also be used to implement Graphs. (Adjacency list representation)
- Implementing Hash Tables : Each Bucket of the hash table can itself be a linked list.
- A polynomial can be represented in an array or in a linked list by simply storing the coefficient and exponent of each term.
- For any polynomial operation , such as addition or multiplication of polynomials , linked list representation is more easier to deal with.
- Linked lists are useful for dynamic memory allocation.
- All the running applications are kept in a circular linked list and the OS gives a fixed time slot to all for running. The Operating System keeps on iterating over the linked list until all the applications are completed.
For more information on Linked list, https://programmerprodigy.code.blog/2020/04/25/linked-list/
4.Stack:
Now stack works on the concept of LIFO , which means last element in will be the first element out . For only understanding purpose we take stack to be horizontal.
For our conceptual understanding consider a stack of plates example , you have to put plate one after another and can only take the top most plate out .
Now the problem with Stack array was that , it was not scalable , our problems our going to be static in nature .Hence we use Linked list approach or vector approach or Dynamic memory allocation approach to counter this.

Applications of Stack:
- To convert and evaluate expressions (postfix, prefix & infix).
- To perform the Undo Sequence.
- To keep the page visited history in Web browsers.
- Uses of the stack in recursion.
- Application of Stack in Tree Traversals.
- To check the correctness of the parentheses sequence.
For more information on Stacks, https://programmerprodigy.code.blog/2020/04/22/stacks-and-queues-using-linked-list/
5.Queue:
Now Queue works on the concept of first element pushed will be last element to be first out , for conceptual reasons we use queue to be Vertical.
For our conceptual understanding , we use an example of a line at a store , the first person who arrived gets served first ,

Now the problem with queue array was that , it was not scalable , our problems our going to be static in nature .Hence we use Linked list approach or vector approach or Dynamic memory allocation approach to counter this .

5.1.Priority Queue:
Queues maintain the order of elements using first in, first out (FIFO) ordering. A priority queue instead of using FIFO ordering, elements are dequeued in priority order.
A priority queue can have either a:
- Max-priority: The element at the front is always the largest.
- Min-priority: The element at the front is always the smallest.
A priority queue is especially useful when you need to identify the maximum or minimum value within a list of elements.

Applications of Queues:
- Job scheduler operations of OS like a print buffer queue, keyboard buffer queue to store the keys pressed by users
- Job scheduling, CPU scheduling, Disk Scheduling
- Priority queues are used in file downloading operations in a browser
- Data transfer between peripheral devices and CPU.
For more information on Queue, https://programmerprodigy.code.blog/2020/04/22/stacks-and-queues-using-linked-list/
6.Trees:
A tree is a finite set of nodes with one specially designated node called the root and the remaining notes are partitioned into n>=0 disjoint sets T1 and Tn where each of those sets is a tree. T1 to Tn are called the sub trees of the root.

6.1.Binary Trees: A tree which has a max 2 child nodes ,along with a root node . Ex -> A is root node, also every node has a max of 2 child nodes .
A general representation of binary tree structure.
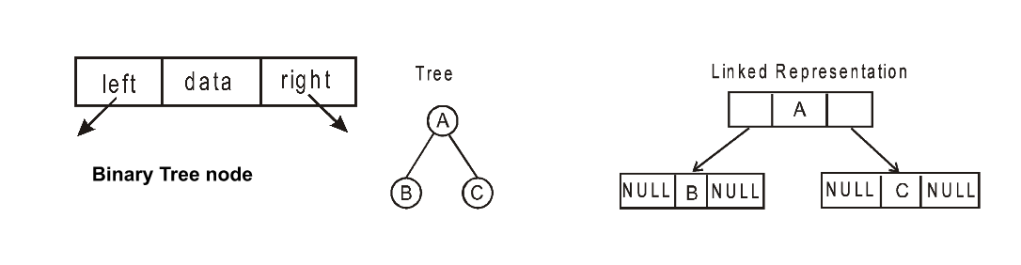
6.2.Binary Search Tree: A binary tree which keeps the keys in a sorted order for faster lookup.
It is mainly used for insertion, deletion and searching of elements. The Structure of binary search trees is defined as,
- All keys in the left sub tree < root.
- All keys in the right sub tree > root.
- The right and left sub trees are also binary search trees.

6.3.Heap: A binary in which all nodes in the tree are in a specific order. There are 2 types of heap, typically:
- Max Heap: all parent node’s values are greater than or equal to children node’s values, root node value is the largest.
- Min Heap: all parent node’s values are less than or equal to children node’s values, root node value is the smallest.

6.4.Threaded Binary Tree: To utilize further more memory , we use leaf nodes. Where Leaf nodes where pointing to NULL, which would have been a waste.

The leftmost and right most leaf node pointer , point towards a new Node called as Head or Dummy Node . left _thread and right_thread =1 means they are pointing towards ancestors , whereas =0 means they are pointing towards child’s
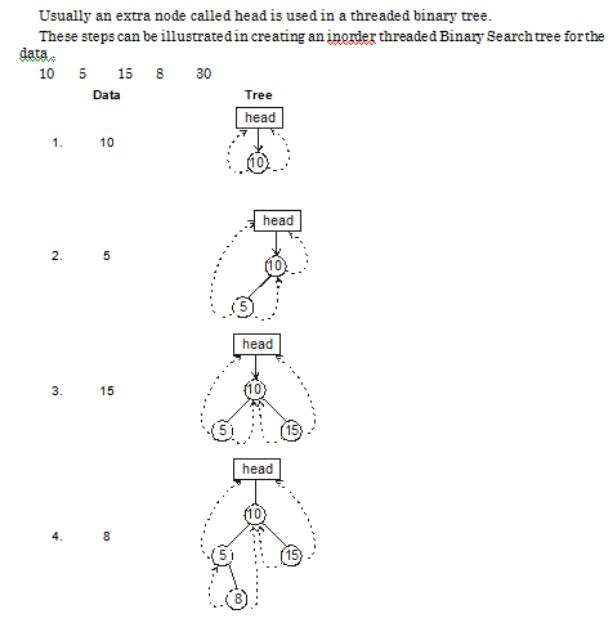
We can implement all the tree in array, but the array approach is not scalable as array are of fixed size and If the tree is not complete we will end up wasting a lot of space.
There are different ways to traverse a tree,
1.Recursive functions: In recursive functions, it keeps on iterating until it reaches the required node by calling the same function just changing it’s passing para meter. We don’t prefer recursive functions as they,
- Add overheads, because when a function is called and returned , an internal stack is used.
- Execution is slower because control has to be transferred to the function and back.
- There is a possibility of the over flow of the internal stack
2.Iterative functions: comparatively tough to implement, but are faster in execution as there is no use of internal stack.
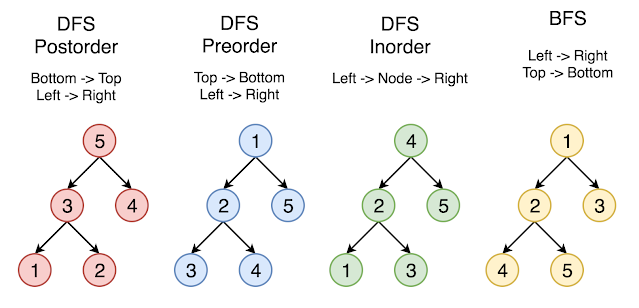
Applications of Trees:
- Implementing the hierarchical structures in computer systems like directory and file system
- Implementing the navigation structure of a website
- Code generation like Huffman’s code
- Decision making in gaming applications
- Parsing of expressions and statements in programming language compilers
- Spanning trees for routing decisions in computer and communications networks
- Path-finding algorithm to implement in AI, robotics and video games applications
For more information on,
- Binary trees: https://programmerprodigy.code.blog/2020/05/02/trees-to-binary-trees/
- Binary Search Trees and Threaded binary Trees: https://programmerprodigy.code.blog/2020/05/02/binary-search-tree/
7.Graphs:
A Graph is a non-linear data structure consisting of nodes and edges. The nodes are sometimes also referred to as vertices and the edges are lines or arcs that connect any two nodes in the graph.
A graph data structure (V, E) consists of:
- A collection of vertices (V) or nodes.
- A collection of edges (E) or paths.


There are three major ways to represent graphs,

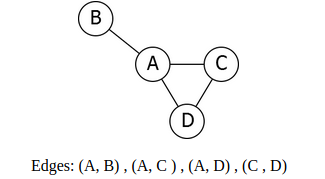
1.Edge List:
To list an edge, we have an array of two vertex numbers containing the vertex numbers of the vertices that the edges are incident on.
Consider the following graph example,
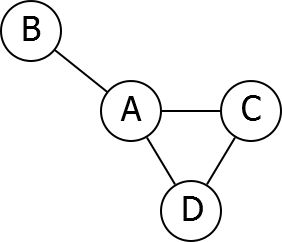
2. Adjacency Matrix:
The adjacency matrix A of a graph G is a two dimensional array of n × n elements where n is the numbers of vertices. The entries of A are defined as
- A[i][j] = 1, if there exist an edge between vertices i and j in G.
- A[i][j] = 0, if no edge exists between i and j.
Consider the following graph example,
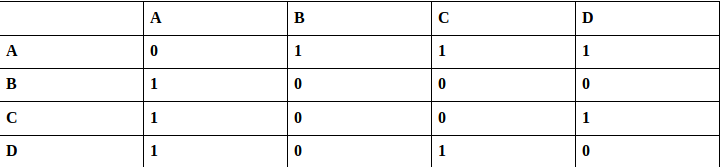
It uses arrays and hence is memory inefficient.
3.ADJACENCY LIST:
An adjacency list represents a graph as an array of linked lists.
The index of the array represents a vertex and each element in its linked list represents the other vertices that form an edge with the vertex.
Let us consider this example,

Ways to traverse a graph:
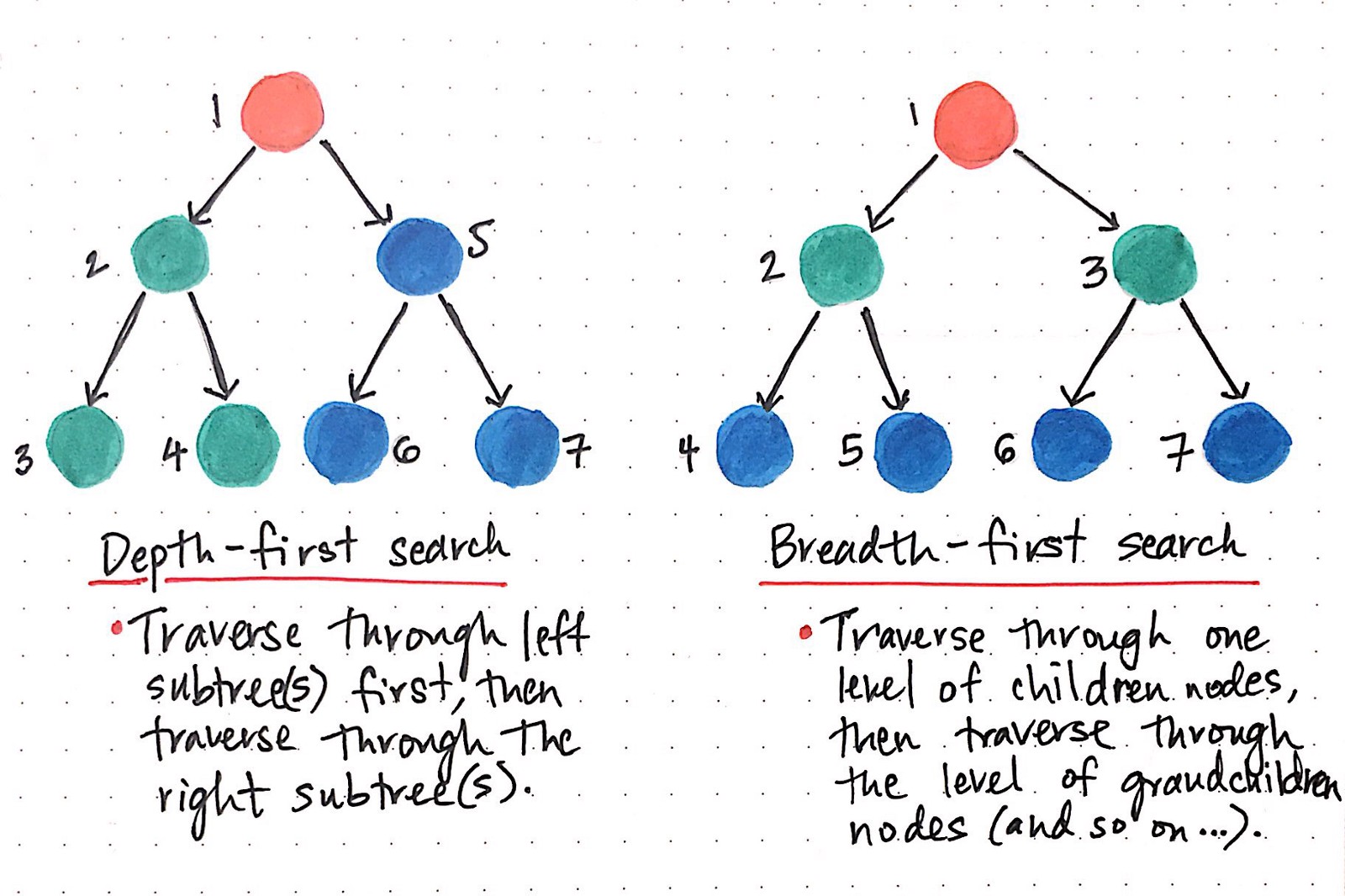
1.DEPTH FIRST SEARCH (DFS):
Starting from vertex ‘v’, we follow a path in the graph as deeply as we can go marking the vertices in the path as ‘visited’. When there are no adjacent vertices that are not visited, we proceed backwards (back track) to a vertex in the path which has an ‘unvisited’ adjacent vertex and proceed from this vertex. The process continues till all vertices have been visited.
2.BREADTH FIRST SEARCH (BFS):
BFS starts with the root node and explores each adjacent node before exploring node(s) at the next level. BFS makes use of the adjacency list data structure to explore the nodes adjacent to the visited (current) node.
Applications of Graphs:
- Representing networks and routes in communication, transportation and travel applications
- Routes in GPS
- Interconnections in social networks and other network based applications
- Resource utilization and availability in an organization
- Robotic motion and neural networks
For more information on graphs, https://programmerprodigy.code.blog/2020/10/22/basics-of-graphs/
8.Hash table:
To search for a specific element, we will look at just a specific position. The element will be found there if it was kept there in the first place. Hence, to place an element, we will first calculate its location, place it there so that it can be retrieved from that position.
In hashing, the address or location of an identifier X is obtained by using some function f(X) which gives the address of X in a table.

Few of different hashing functions:
1. Division hash function: The modulus operator can be used as a hash function. The identifier X is divided by some number M and the remainder is used as the hash address of X.
f(x) = X mod M.
Example: If X = 134 and M = 31 then f(X)= X mod M = 134 mod 31 =10
2.Folding hash function:
In this method, the identifier X is partitioned into several parts all of the same length except the last. These parts are added to obtain the hash address. Addition is done in two ways,
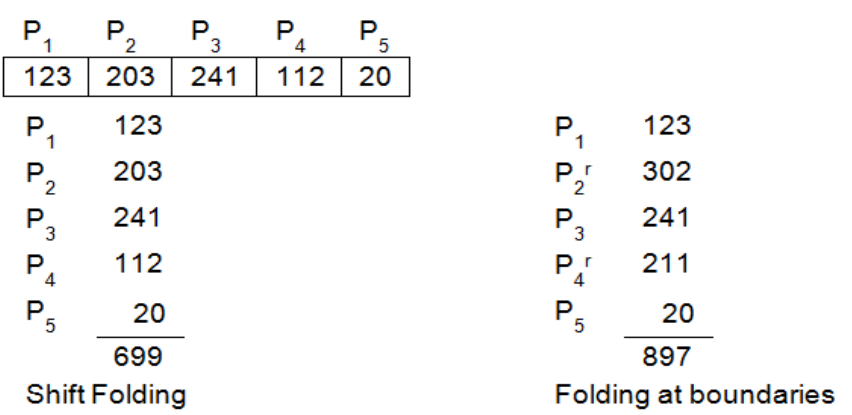
1.Shift Folding: All parts except the last are shifted so that their least significant bits correspond to each other.
For example, the hash function could form groups of three from the key 12320324111220. To determine the index to which the key is mapped the hash function “shifts” each set of digits under the other and adds them
2.Folding on the boundaries: The identifier is folded at the part boundaries and the bits falling together are added.
Group the digits in the search key as in shift folding but the middle numbers are folded on the boundary between the first group and the middle group and they are thus reversed.
Applications of a Hash Table
Hash tables are good in situations where you have enormous amounts of data from which you would like to quickly search and retrieve information. A few typical hash table implementations would be in the following situations:
- It is used for mapping the file name to the path of the file which makes it easy to search a file using filename.
- When a password is entered on a website, a hash of the password is computed on the client-side which is then sent to the server through the network. At the server, the hash code is matched and the password is verified. This is done to avoid sniffing.
- To identify the keywords in a programming language, the compiler uses the hash table to store these keywords and other identifiers to compile the program.
- For telephone book databases. You could make use of a hash table implementation to quickly look up John Smith’s telephone number.
- For electronic library catalogs. Hash Table implementations allow for a fast find among the millions of materials stored in the library.
For more information on Hashing, https://programmerprodigy.code.blog/2021/01/20/intro-into-hashing/
- GitHub Repository for all the code, https://github.com/kakabisht/Data-structures.
- Different approaches to algorithms: https://programmerprodigy.code.blog/2020/12/19/basics-of-an-algorithm-and-different-algorithmic-approaches/

{kind=link}
{kind=link}
{kind=link}
{kind=link}
well written and easy to uderstand .
LikeLike