Hello, this blog contains the basic concept of hashing, hashing terminologies, various hashing functions, various collision resolution strategies, chaining with and without replacement, chaining using linked list and extendible hashing.
At the end it contains link to a GitHub repository, along with my another blog on encryption and decryption.
Concept of Hashing:
To search for a specific element, we will look at just a specific position. The element will be found there if it was kept there in the first place. Hence, to place an element, we will first calculate its location, place it there so that it can be retrieved from that position.
In hashing, the address or location of an identifier X is obtained by using some function f(X) which gives the address of X in a table.

Hashing Terminology:
- Hash Function: A function that transforms a key X into a table index is called a hash function.
- Hash address: The address of X computed by the hash function is called the hash address or home address of X.
- Hash Table: The hash table is the sequential memory used to store identifiers.
- Bucket: Each hash table is partitioned into ‘b’ buckets ht[0]……ht[b-1].
- Each bucket is capable of holding ‘s’ records. Thus, a bucket consists of ‘s’ slots. When s = 1, each bucket can hold 1 record.
- The function f(X) maps an identifier X into one of the ‘b’ buckets i.e from 0 to b-1.
- Synonyms: Usually, the total number of possible values for identifier X is much larger than the hash table size. Therefore the hash function f(X) must map several identifiers into the same bucket.
- Two identifiers I1 and I2 are synonyms if f(I1) = f(I2)
- Collision: When two non identical identifiers are mapped into the same bucket, a collision is said to occur, i.e. f (I1) = f(I2). Hence all synonyms occupy the same bucket.
- Overflow: An overflow is said to occur when an identifier gets mapped onto a full bucket.
- When s = 1, i.e., a bucket contains only one record, collision and overflow occur simultaneously. Such a situation is called a Hash clash.
- Load factor: If n is the total number of identifiers in the table and t is the table size, the load factor is :
- lf = n/t It represents the fraction of the table that is occupied.
- Perfect Hash Function : Given a set of keys k1, k2, … kn, a perfect hash function, f, is such that f(ki) != f(kj) for all distinct i and j.
For an example, Let us consider a hash table with b= 26 buckets (from 1 to 26) each having 2 slots, i.e. s = 2. Assume that there are 10 distinct identifiers each beginning with a letter.
Hash function f(X) = Number corresponding to the first letter of identifier i.e. if X = ‘A’, then f(X) = 1.
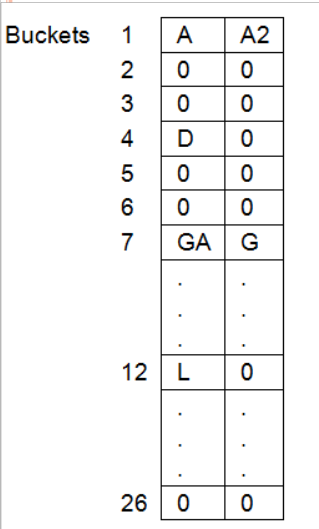
If the identifiers are GA, D, A, G, L, A2, A1, A3, A4, E . Their hash addresses will be 7,4,1,7,12,1,1,1,1,5 respectively. GA and G are :
synonyms. A, A2, A1, A3 and A4 are synonyms. When G gets hashed into bucket 7, a collision is said to occur. When A1 gets hashed into bucket 1, which already contains A and A2, an overflow occurs.
Hash Function:
Desirable Characteristics of a Hashing Function
- It should be easily computable.
- It should minimize the number of collisions.
- The hash function should compute the address, which depends on all or most of the characters in the identifier.
- It should yield uniform bucket addresses for random inputs. Such a function is called a uniform hash function.
1.Mid Square hash function:
This is a very widely used function in symbol table applications. It is the “middle of square” function, which is computed by squaring the identifiers and using an appropriate number of bits from the middle to obtain the bucket address.
Example: (the size of the hash table = 100), If X = 225, X2 = 050625 then hash address = 06
For more information,
2.Division hash function
The modulus operator can be used as a hash function. The identifier X is divided by some number M and the remainder is used as the hash address of X.
f(x) = X mod M.
The best choice for M is that it should be a prime number.
Example: If X = 134 and M = 31 then f(X)= X mod M = 134 mod 31 =10
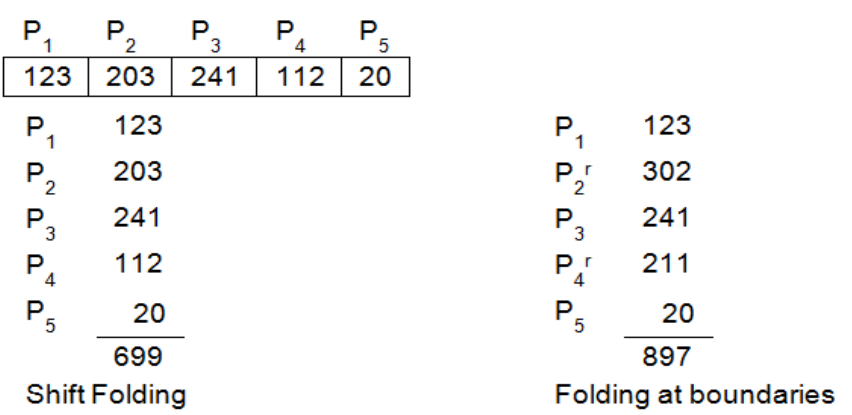
3.Folding hash function:
In this method, the identifier X is partitioned into several parts all of the same length except the last. These parts are added to obtain the hash address.
Addition is done in two ways.
1.Shift Folding: All parts except the last are shifted so that their least significant bits correspond to each other.
For example, the hash function could form groups of three from the key 12320324111220. To determine the index to which the key is mapped the hash function “shifts” each set of digits under the other and adds them
2.Folding on the boundaries: The identifier is folded at the part boundaries and the bits falling together are added.
Group the digits in the search key as in shift folding but the middle numbers are folded on the boundary between the first group and the middle group and they are thus reversed.

Heya just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different web browsers and both show the same results.
LikeLike