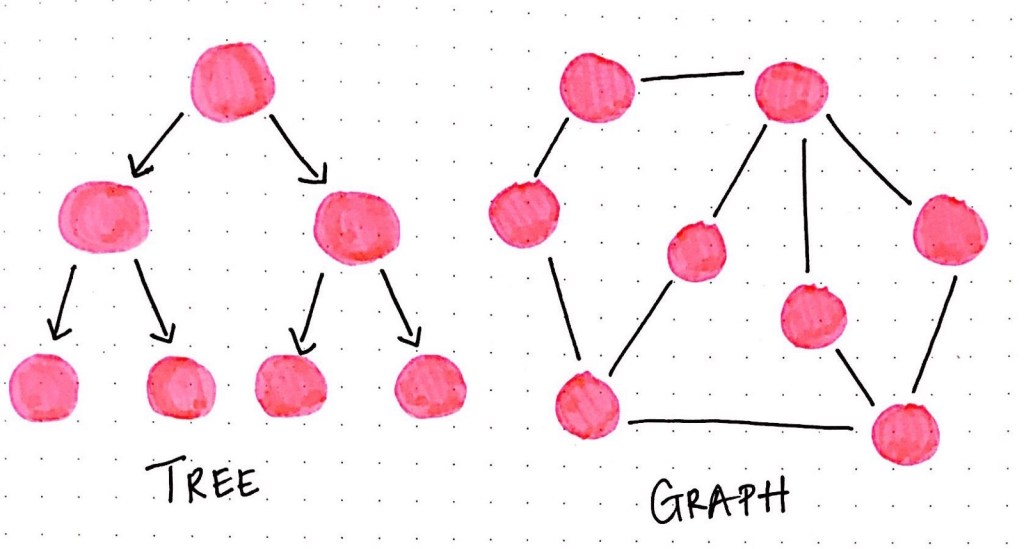
I took this course, Algorithms on Graphs by University of California San Diego & National Research University Higher School of Economics. It had wonderful explanations of basics of graphs.
Q.What is a Graph?
A Graph is a non-linear data structure consisting of nodes and edges. The nodes are sometimes also referred to as vertices and the edges are lines or arcs that connect any two nodes in the graph.
A graph data structure (V, E) consists of:
- A collection of vertices (V) or nodes.
- A collection of edges (E) or paths.


Use cases for Graph data structure:
- use a graph to find out whether two places on a road-map are connected and what is the shortest distance between them
- simulating electrical circuits to find out current flows and voltage drops at various points in the circuit.
- algorithms used in social media applications

Graph Terminology Used:
- Path: It is the sequence of vertices in which each pair of successive vertices is connected by an edge.
- Cycle: It is a path that starts and ends on the same vertex.
- Simple Path: It is a path that does not cross itself that is, no vertex is repeated (except the first and the last). Also, simple paths do not contain cycles.
- Length of a Path: It is the number of edges in the path. Sometimes it’s the sum of weights of the edges also in case of weighted graphs.
- Degree of a Vertex: It is the number of edges that are incident to the vertex.
- Indegree of a Vertex: The indegree of a vertex is the number of edges for which it is head i.e. the numbers edges coming to it.
- Outdegree of a vertex: The out degree of a vertex is the number of edges for which it is the tail i.e. the number of edges going out of it. A node whose outdegree is 0 is called a sink node.
- Adjacent vertices: If (Vi, Vj) is an edge in G, then we say that Vi and Vj are adjacent and the edge (Vi, Vj) is incident on Vi and Vj.
different types of graphs:
1. Undirected Graph:
A graph is an undirected graph if the pairs of vertices that make up the edges are unordered pairs.
i.e. an edge(Vi, Vj ) is the same as (Vj, Vi). The graph G1 shown above is an undirected graph.
2.Directed Graph:
In a directed graph, each edge is represented by a pair of ordered vertices.
i.e. an edge has a specific direction. In such a case, edge (Vi, Vj) ≠ (Vj, Vi)

3.Complete Graph:
If an undirected graph has n vertices, the maximum number of edges it can have is nC2 = n (n-1) / 2. If an undirected graph G has ‘n’ vertices and nC2 edges, it is called a complete graph.
If the graph G is directed and has n vertices, G is complete if it has n(n-1) edges.
4.Multigraph:
A multigraph is a graph in which the set of edges may have multiple occurrences of the same edge.

5.Cycle in graph?
Cycle: A cycle is a path whose first and last vertices are the same. For example, nodes abcd are cyclic.
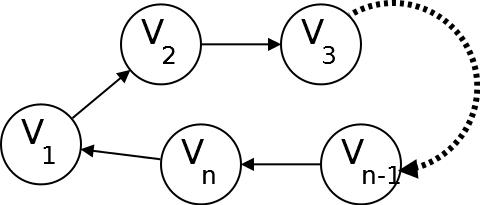
Acyclic: A graph with no cycles is called an acyclic graph. A directed acyclic graph is called dag. For example, in second example there is no cycle

6.Connected Graph:
Two vertices Vi and Vj are said to be connected if there is a path in G from Vi to Vj.
1.Strongly Connected Graph: A directed graph G is said to be strongly connected if for every pair of distinct vertices Vi, Vj, there is a directed path from Vi to Vj and also from
Vj to Vi.
2.Weakly Connected Graph : A directed graph G is said to be weakly connected there exists at least one set of distinct vertices Vi, Vj, such that there is a directed path from Vi to Vj but no path from Vj to Vi.

7.Subgraph:
A subgraph of G is a graph G ′such that , V(G′) ⊆ V(G) and E(G′) ⊆ E(G)

8.Weighted Graph or Network:
A number (weight) may be associated with each edge of a graph. Such a graph is called a weighted graph or a network.
Example The number may represent the distance, cost, etc.

Ways to Represent graphs:

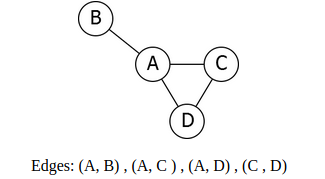
A.Edge List:
To list an edge, we have an array of two vertex numbers containing the vertex numbers of the vertices that the edges are incident on.
Consider the following graph example,
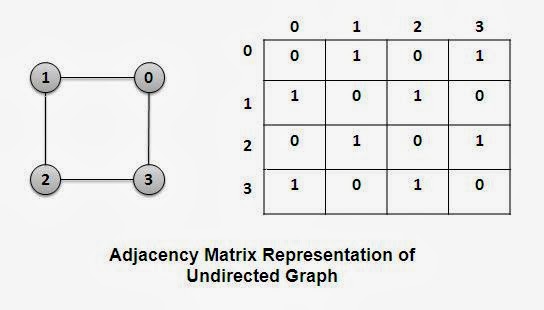
B. Adjacency Matrix:
The adjacency matrix A of a graph G is a two dimensional array of n × n elements where n is the numbers of vertices. The entries of A are defined as
- A[i][j] = 1, if there exist an edge between vertices i and j in G.
- A[i][j] = 0, if no edge exists between i and j.
- Undirected graph: The degree of vertex i is the number of 1’s in its row (or the sum of row i )
- Directed graph
- (Indegree) : Total number of 1’s in column i.
- (Outdegree) : Number of 1’s in row i.

Code to implement Adjacency Matrix,
#include <iostream>
#include <cstdlib>
using namespace std;
class Graph
{
protected:
int value;
int **graphm;
public:
Graph(int value)
{
this->value = value;
graphm = new int*[value];
int k, j;
for (k = 0; k < value; k++)
{
graphm[k] = new int[value];
for (j = 0; j < value; j++)
{
graphm[k][j] = 0;
}
}
}
void newEdge(int head, int end)
{
if (head > value || end > value || head < 0 || end < 0)
{
cout << "Invalid edge!\n";
}
else
{
graphm[head - 1][end - 1] = 1;
graphm[end - 1][head - 1] = 1;
}
}
void display()
{
int i, p;
for (i = 0; i < value; i++)
{
cout<<i+1<<"Row: \t";
for (p = 0; p < value; p++)
{
cout <<p+1<<"Column:" << graphm[i][p] << " ";
}
cout << endl;
}
}
};
int main()
{
int vertex, numberOfEdges, i, head, end;
cout << "Enter number of nodes: ";
cin >> vertex;
numberOfEdges = vertex * (vertex - 1);
Graph g1(vertex);
for (int i = 0; i < numberOfEdges; i++)
{
cout << "Enter edge ex.1 2 (-1 -1 to exit): \n";
cin >> head >> end;
if ((head == -1) && (end == -1))
{
break;
}
g1.newEdge(head, end);
}
cout<<"\n";
g1.display();
cout << endl;
return 0;
}
Consider the following graph example,
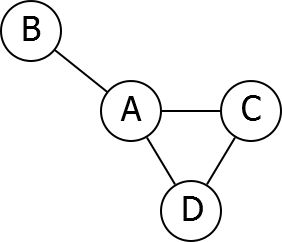
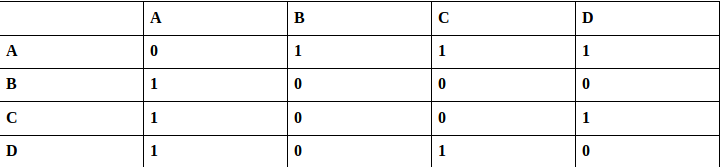
It uses arrays and hence is memory inefficient.
C.ADJACENCY LIST:
An adjacency list represents a graph as an array of linked lists.
The index of the array represents a vertex and each element in its linked list represents the other vertices that form an edge with the vertex.
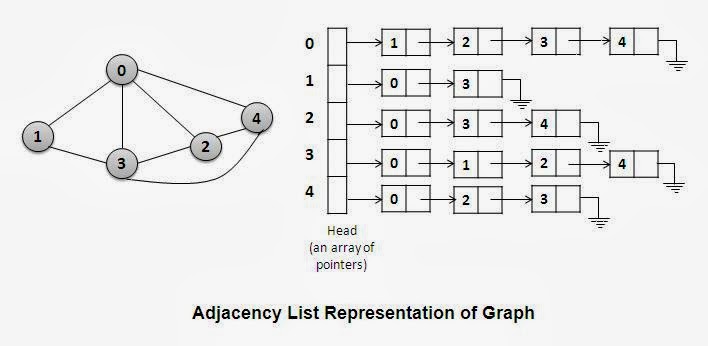
- From the adjacency list we can calculate the outdegree of any vertex i. The total number of nodes in list ‘i’ is its outdegree.
- To obtain the indegree, we can construct an inverse adjacency list. The inverse adjacency list.
#include <iostream>
#include <cstdlib>
#include <list>
#include <vector>
using namespace std;
int main()
{
int vertices, edges, v1, v2, weight;
cout<<"Enter the Number of Vertices -\n";
cin>>vertices;
edges = vertices * (vertices - 1);
vector< list< pair<int, int> > > adjacencyList(vertices + 1);
cout <<"Enter edges ex.V1 V2 W (-1 -1 -1 to exit): \n";
for (int i = 0; i < edges; ++i) {
cin>>v1>>v2>>weight;
if ((v1 == -1) && (v2 == -1) && (weight ==-1))
{
break;
}
// Adding Edges to the Graph
adjacencyList[v1].push_back(make_pair(v2, weight));
adjacencyList[v2].push_back(make_pair(v1, weight));
}
cout<<"\nThe Adjacency List-\n";
// Printing Adjacency List
for (int i = 1; i < adjacencyList.size(); ++i) {
cout<<"AdjacencyList at "<< i<<"\t";
list< pair<int, int> >::iterator itr = adjacencyList[i].begin();
while (itr != adjacencyList[i].end()) {
cout<<" -> "<<(*itr).first<<"("<<(*itr).second<<")";
++itr;
}
cout<<"\n";
}
return 0;
}
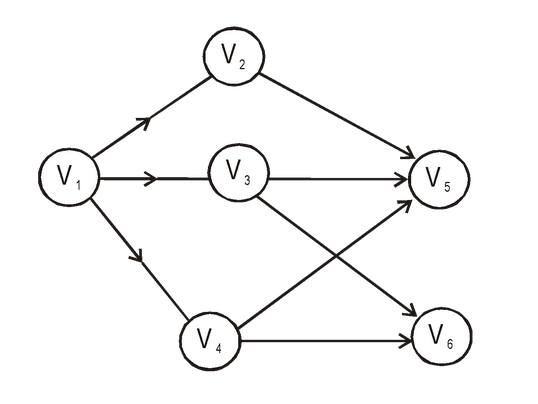
Let us consider this example,

For more information,
- https://runestone.academy/runestone/books/published/cppds/Graphs/AnAdjacencyMatrix.html
- https://medium.com/the-programming-club-iit-indore/graphs-and-trees-using-c-stl-322e5779eef9
GRAPH TRAVERSALS:
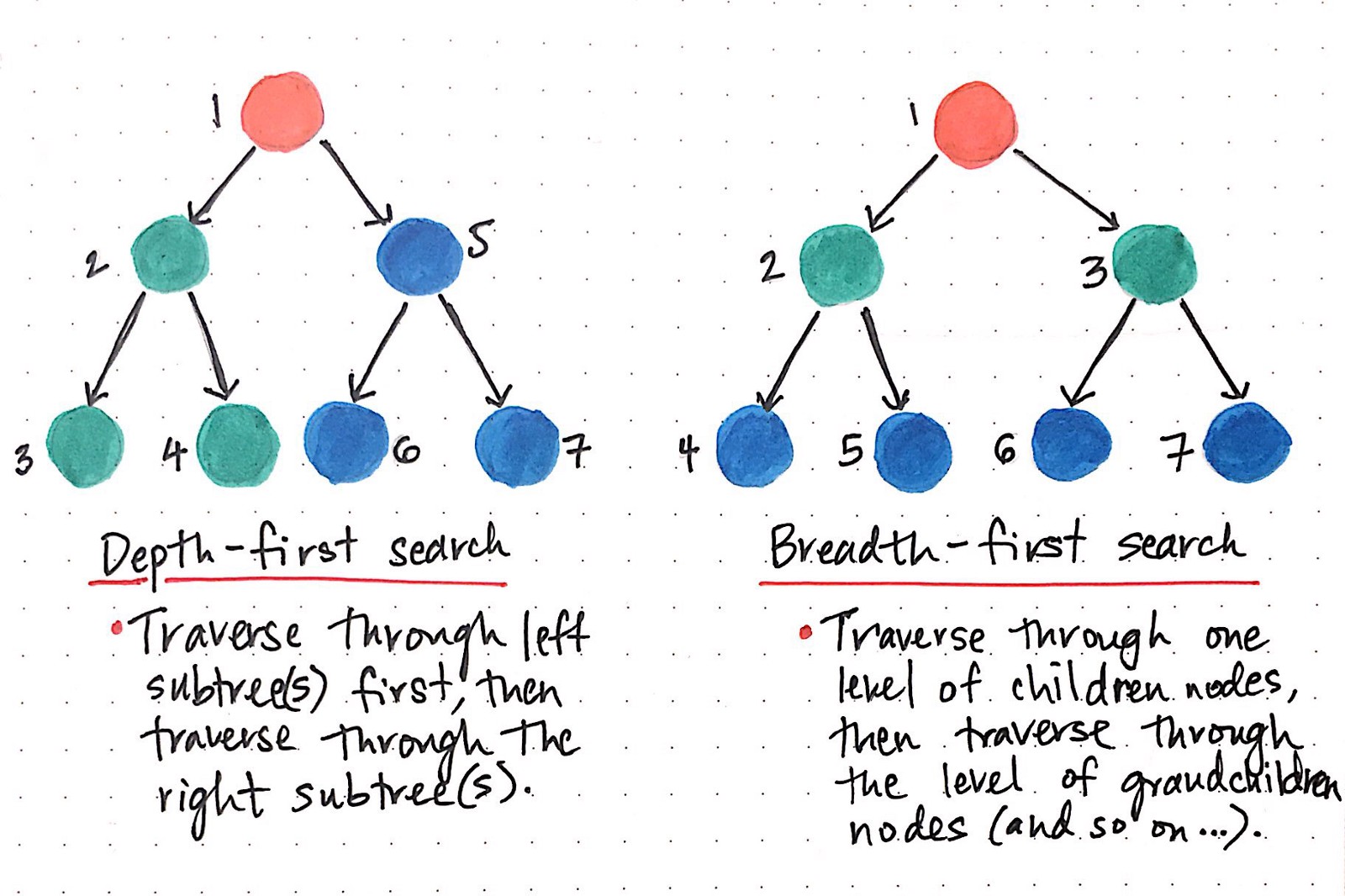
1.DEPTH FIRST SEARCH:
Starting from vertex ‘v’, we follow a path in the graph as deeply as we can go marking the vertices in the path as ‘visited’. When there are no adjacent vertices that are not visited, we proceed backwards (back track) to a vertex in the path which has an ‘unvisited’ adjacent vertex and proceed from this vertex. The process continues till all vertices have been visited.

Algorithm: Depth-first search (Graph G, Souce_Vertex S)
- Create a stack STK to store the vertices.
- Push the source vertex S in the stack ‘STK’.
- While the stack STK is not empty
- Pop the vertex U from the top of the stack. i.e Vertex U = STK.top(), STK.pop()
- If the vertex U is not visited
- Explore the vertex U and mark U as visited.
- For every vertex V adjacent to vertex U
- Push the vertex V in the stack STK
The function for implementing it would be,
void Graph::depth_first_search(int start_vertex){
int current_v = start_vertex;
this->discovered[current_v] = true;
EdgeNode *p = this->edges[current_v];
process_vertex_early(current_v);
while(p != NULL){
int neighbor_v = p->key;
if(!this->discovered[neighbor_v]){
//this->discovered[neighbor_v] = true;
this->parent[neighbor_v] = current_v;
process_edge(current_v, neighbor_v);
depth_first_search(neighbor_v);
}
//2nd case is needed because 1st case isn't enough to visit all edges (because 1st case sets all neighbors
//to discovered which excludes some visits to edges later)
else if(((!this->processed[neighbor_v]) && (this->parent[current_v] != neighbor_v)) || (this->directed)){
process_edge(current_v, neighbor_v);
}
p = p->next;
}
this->processed[current_v] = true;
}
We can implement DFS using various other data structures for storing graph and for searching in it.
Applications of DFS:
- Minimum Spanning Tree
- Topological sorting
- To solve puzzle/maze which has one solution
For more information,
- https://brilliant.org/wiki/depth-first-search-dfs/
- https://algotree.org/algorithms/tree_graph_traversal/depth_first_search/
2.BREADTH FIRST SEARCH:
BFS is an algorithm for traversing an unweighted Graph or a Tree. BFS starts with the root node and explores each adjacent node before exploring node(s) at the next level.
BFS makes use of the adjacency list data structure to explore the nodes adjacent to the visited (current) node.

Algorithm: Breadth-first search (Graph G, Souce_Vertex S)
- Create a queue Q to store the vertices.
- Push the source vertex S in the queue Q.
- Mark S as visited.
- While the queue Q is not empty
- Remove vertex U from the front of the queue. i.e Vertex U = Q.front(), Q.pop()
- For every vertex V adjacent to the vertex U
- If the vertex V is not visited
- Explore the vertex V and mark V as visited.
- Push the vertex V in the queue Q.
The function for implementing it would be,
void Graph::breadth_first_search(int start_vertex){
initialize_search();
queue<int> q;//queue of vertices still left to visit
int current_v; //current vertex
EdgeNode *p; //temporary pointer
q.push(start_vertex);
this->discovered[start_vertex] = true;
while(!q.empty()){
current_v = q.front();
q.pop();
process_vertex_early(current_v);
p = this->edges[current_v];
while(p != NULL){
int neighbor_v = p->key;
if(!this->discovered[neighbor_v]){
//add to Q and set to discovered
q.push(neighbor_v);
this->discovered[neighbor_v] = true;
this->parent[neighbor_v] = current_v;
}
if(!this->processed[neighbor_v] || this->directed){
process_edge(current_v, neighbor_v);
}
p = p->next;
}
this->processed[current_v] = true;
}
initialize_search();
}

We can implement BFS using various other data structures for storing graph and for searching in it.
Application of BFS :
- Minimum Spanning Tree or shortest path
- Peer to peer networking
- Crawler for search engine
- Social network websites – to find people with a given distance k from a person using BFS till k levels.
For more information,
- https://algotree.org/algorithms/tree_graph_traversal/breadth_first_search/
- https://brilliant.org/wiki/breadth-first-search-bfs/
Difference between DFS and BFS
For more information,

One thought on “Basics of Graphs”