Chaining:
1.Chaining without Replacement:
The hash address of an identifier X is computed.
- If this position is vacant, it is placed there.
- It its position is occupied by another identifier Y, the identifier X is put in the next vacant position and a chain is formed to the new position i.e. from Y to X.
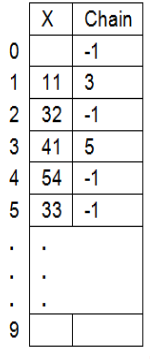
Example: Identifier is 11, 32, 41, 54, 33.
Hash function: f(x) = X mod 10 and Table size = 10
- Identifier 11 and 32 get hashed into positions 1 and 2 respectively.
- The hash address of 41 is 1 but its position is occupied, hence it is put at position 3 and a chain is formed.
- 54 stored at position 4
- The hash address of 33 is 3 but it is occupied. So 3 is placed at position 5 and a chain is formed from position 3 to 5 as shown.
Advantage:
- Since identifiers are chained, we have to only use the chains to locate an identifier.
- It is more efficient as compared to the previous methods.
Disadvantage:
- The main idea is to chain all identifiers having same hash address (synonyms). However, when an overflow occurs, an identifier occupies the position of another identifier. Hence, even non-synonyms get chained together thereby increasing complexity.
2.Chaining with Replacement:
This is an improvement over the above method. As we saw above, even non synonyms get chained. To avoid this from happening, if we find that another identifier Y which is a non-synonym, is occupying the position of an identifier X, X replaces Y and then Y is relocated to a new position.
It will not make a difference to Y since Y was anyway not in its own bucket. But by placing X in its own bucket, we are improving the efficiency.
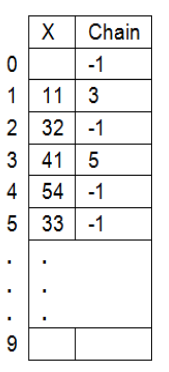
Let us consider the same example as earlier. Here, 11, 32, 41 and 54 get placed in the same way as before.
However, when 33 has to be placed, its position is occupied by 41. Thus, 33 replaces 41 and 41 is now put into the next empty slot i.e 5 and the chain from element 11 at position 1 is modified.
- 11,41===1
- 33===3
- We will swap 41 & 33
Advantages:
- Most of the identifiers occupy their valid positions.
- Searching becomes easier since only the synonyms are chained.
Disadvantages:
- Insertions and deletions take more time.
3.Chaining using linked lists:
All of the above methods suffer from a variety of problems.
- Limited amount of space, due to which the table can become full.
- The complexity of chaining which results in poor efficiency.
Obviously the best method would be to have unlimited amount of space for each bucket so that we could put in as many identifiers as we want without any overflow taking place.
Advantages
- Most efficient method to resolve collision.
- There is no limit on the number of identifiers.
- Searching, Insertion and Deletions are done efficiently.
- The hash table will never be ‘full’.
Disadvantages
- If many identifiers are put into a single list, searching time within a bucket will increase.
- Handling of the pointer array and linked lists is more complex as compared to simple arrays.
EXTENDIBLE HASHING
Reason for Extendible hashing :
- Most records have to be stored in disk
- Disk read/write operations much more expensive than operations in main memory
- Regular hash tables need to examine several disk blocks when collisions occur
- We want to limit number of disk accesses for find/insert operations
Concept :
- Retrieval to be performed in two disk accesses and Insertion also in few accesses.
- This can be achieved by using a tree structure.
- The tree is an M-ary tree (degree M) which allows M-way branching.
- This means that as the branching increases, depth of the tree decreases.
- A complete Binary tree has height (log2N) whereas a complete M-ary tree has height of (log M/2 N). As M increases, the depth decreases.

Procedure:
- Hash the key of each record into a reasonably long integer to avoid collision
- Adding 0’s to the left so they have the same length
- Build a directory
- The directory is stored in the primary memory
- Each entry in the directory points to a leaf
- Directory is extensible
- Each leaf contains M records,
- Stored in one disk block
- Share the same D number of leading digits
For more information on hashing,
- http://cse.uaa.alaska.edu/~afkjm/csce311/fall2018/handouts/hashing-drozdek.pdf
- https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-006-introduction-to-algorithms-fall-2011/lecture-videos/MIT6_006F11_lec08.pdf
- GitHub Repository for code: https://github.com/kakabisht/Data-structures
- Blog on Encryption and Decryption:https://programmerprodigy.code.blog/2020/04/10/encryption-and-decryption/

Heya just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different web browsers and both show the same results.
LikeLike