Consider times in your life when someone said something that left you speechless. It’s the ideal moment for a witty comeback, but you have nothing to say. You think of the perfect response after walking away, but it is too late. The moment has passed us. This is an example of how some data degrades value over time.
Some data comes as an unending stream of events and is best analysed while in flight. They process raw data in real-time using streams, and you save only the information and insight that is useful. Streaming data architecture enables developers to analyse time-sensitive data with greater value to generate a real-time situation.
This blog will cover the introduction to streaming data, components of streaming data architecture, integrating batch processing with stream processing, and in depth about Amazon kinesis services such as Kinesis Video Streams, Kinesis Data Streams, Kinesis Data Firehose, and Kinesis Data Analytics .
Q.What do you mean by stream processing?
Stream processing involves ingesting a continuous data stream and analysing, filtering, transforming, or improving the data in real time. This improves visibility into various areas of data activity, such as service consumption, server usage, and device geolocation.
Businesses, for example, can continuously analyse social media streams to watch changes in public attitude toward their brands and products and respond promptly.
Stream processing services and architectures are becoming increasingly popular because they enable developers to mix data feed from multiple sources, and since not all data is produced equally and its value changes.
Q.What is batch processing ?
Before stream processing, vast amounts of data were often stored in a database and processed all at once. They examined this data using batch processing because, as the name implies, they performed it all in one “batch.”
Batch processing collects, stores, and analyses data in fixed-size pieces regularly. The schedule depends on the frequency of data gathering and the related value of the insight gained. This value lies at the heart of stream processing.
There are two issues related to batch processing that impact the value of data
- Batch processing systems divide data into consistent and evenly spaced time intervals. This results in a consistent workload that is predictable but not intelligent. Sessions that begin in one batch may finish up in another. This complicates the examination of connected transactions.
- They have optimised batch architectures to handle enormous amounts of data at once. As a result, an analysis job may have to wait for long periods of time because the queue must be full before processing can begin. While the batch job’s size is consistent, the time in each batch of data is not.
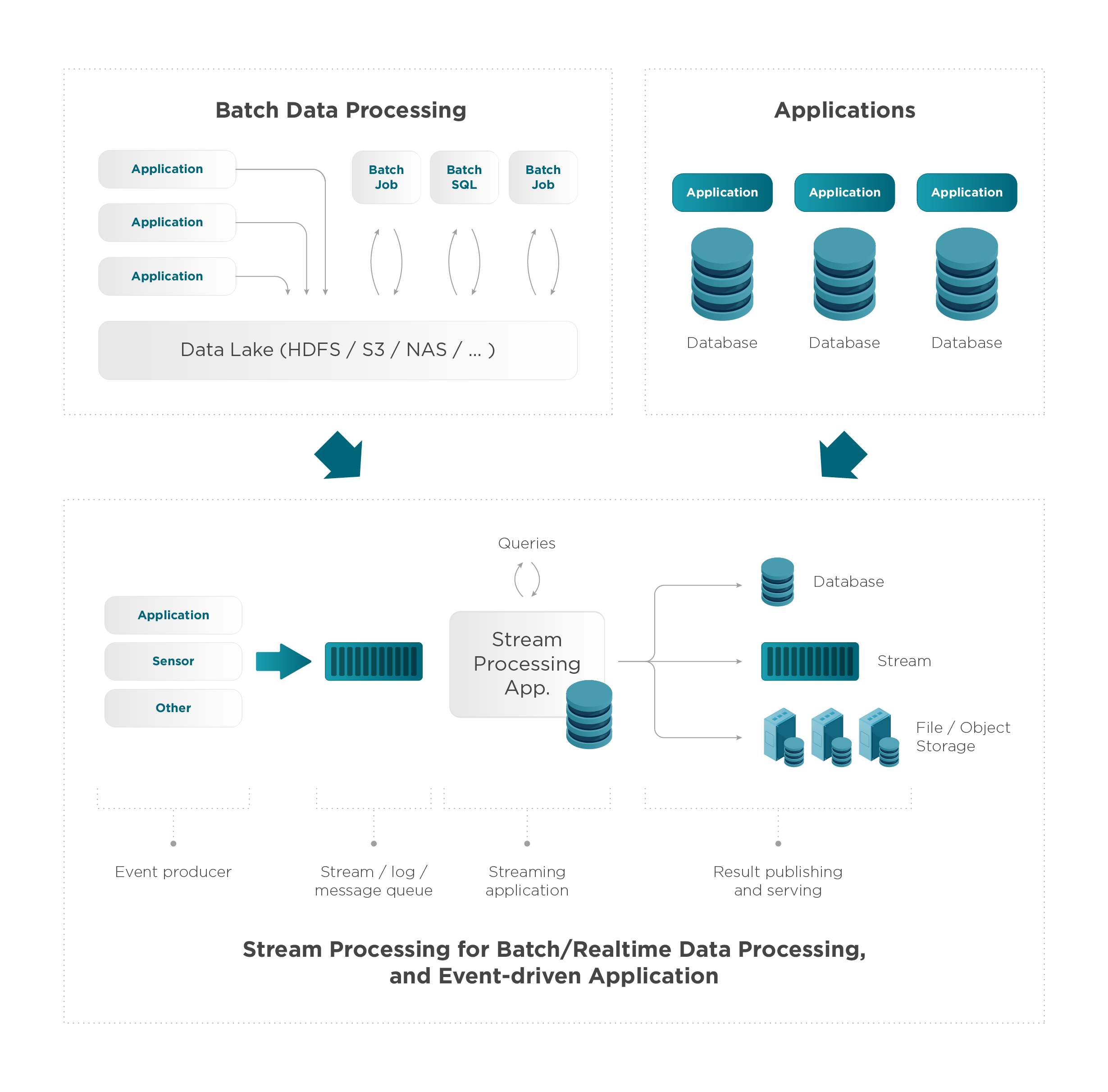
Batch processing is built around a data-at-rest architecture. Before processing can begin, the collection has to be stopped and we must store the data. Subsequent batches of collected data bring the need to create an aggregate across multiple batches. In contrast to this, streaming architectures handle never-ending data flows naturally and with grace. Using streams, patterns detected, results inspected, and we can examine simultaneously multiple streams.

I believe it is crucial to emphasise that batch processing is still required. Stream processing is a supplement to batch computing. Some forms of information require real-time data processing because the data has an actionable value at the collected time and its value diminishes rapidly. Steam processing was developed to solve latency, session boundaries, and unpredictable load.
Q. What are Components of Stream application?
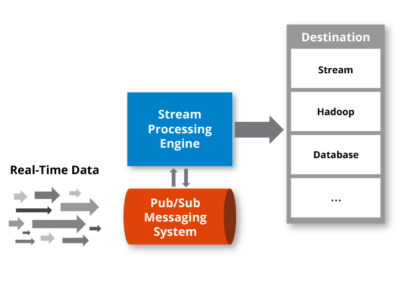
Generally speaking, streaming data frameworks are described as having five layers; the Source, Stream Ingestion, Stream Storage, Stream Processing, and the Destination.
- Data is generated by one or more sources or producers including mobile devices, meters in smart homes, click streams, IoT sensors, or logs.
- Data is gathered at the Stream Ingestion Layer by one or more producers, structured as Data Records, and placed in a data stream.
- They convert it to a common message format and actively stream it.
- We store the data in the Data Stream. Before we can evaluate data with SQL-based analytics tools, data streams from one or more message brokers are gathered, converted, and formatted.
- The outcome could be an API call, an action, a visualisation, an alert, or, in some situations, the creation of a new data stream.
- The Stream Processing Layer is managed by Consumers. Consumers access streams, read data, then process data contained inside a stream.
- The Consumers deliver Data Records to the fifth layer, the destination. Such as a Data Lake or Data Warehouse, durable storage, such as Amazon S3, or Amazon Redshift.
Q. HOW IMPORTANT IS STREAM PROCESSING?
Perhaps a better question is how important it is to have immediate insight into how the business is operating, or how customers are feeling.
Stream processing is a natural fit for time-series data and pattern detection. For example, consider real-time trading in commodities such as stocks; a fraction of a second advantage might translate into millions in profit or loss. What about huge consumer product companies conducting global product releases in which millions of individuals log in at the same moment to buy?
Not every transaction necessitates an immediate response, but many do. The issue is that developers must be able to recognise when something significant occurs and act on it in a meaningful and immediate manner.
Streaming lowers the need for big and expensive shared databases. Because each stream processing application keeps its own data and state when utilising a streaming framework, stream processing fits naturally inside a microservices architecture.
Q. What is Amazon Kinesis?
Amazon Kinesis addressed the complexity and costs associated with data streaming into the AWS cloud. Kinesis makes it simple to gather, process, and analyse numerous sorts of data streams in real time or near real-time, such as event logs, social media feeds, clickstream data, application data, and IoT sensor data.
Kinesis Video Streams, Kinesis Data Streams, Kinesis Data Firehose, and Kinesis Data Analytics are the four services offered by Amazon Kinesis.
- Kinesis Video Streams is a stream processing tool for binary-encoded data including audio and video.
- Base64 text-encoded data is streamed via Kinesis Data Streams, Kinesis Data Firehose, and Kinesis Data Analytics.
- This text-based data comes from sources such as logs, click-stream data, social media feeds, financial transactions, in-game player activity, geolocation services, and IoT device telemetry.

A. Kinsesis Video Streams:
Amazon Kinesis Video streams binary-encoded data into AWS from millions of sources. Traditionally, this is audio and video data, but it can be any type of binary-encoded time-series data.
The AWS SDKs securely stream data to AWS for processing, such as playback, storage, analytics, machine learning, and other tasks.
Kinesis Video Streams support WebRTC, an open-source initiative. This enables bi-directional, real-time media streaming between web browsers, mobile apps, and linked devices.
Kinesis Video Streams price is based on the amount of data imported, consumed, and stored across all video streams in an account.
B. Kinsesis Data Streams:
A Kinesis Data Stream is a collection of Shards. A shard is a collection of Data Records. Data Records comprise a Sequence Number, a Partition Key, and a Data Blob and are saved as an immutable series of bytes.
The Kinesis Data Stream is a Stream Storage Layer and is a high-speed buffer that stores data. Inside Kinesis Data Streams, the Data Records are immutable. We cannot erase data from the stream; instead, it can simply expire.
When constructing a stream, all components related with stream processing. AWS will only provide resources when they are requested. One major point here is that Kinesis Data Streams do not support Auto Scaling.
Customers can subscribe to a shard using Enhanced Fan Out. As a result, it immediately moved data from the shard into a consumer application.
Pricing for Kinesis Data Streams is a little more tricky. The number of shards in a Kinesis Data Stream determines the hourly cost. This fee is assessed regardless of whether data is present in the stream.
- When producers put data into the stream, there is a separate charge.
- When you enable the optional extended data retention, there is an hourly charge per shard for data saved in a stream.
C. Kinsesis Data Firehouse:
Amazon Kinesis Data Firehose, like Kinesis Data Streams, is an AWS data streaming service. While Kinesis Data Streams is very customisable, Data Firehose is essentially a streaming data delivery service where ingested data may be dynamically processed, automatically scaled, and sent to a data store. As a result, Kinesis Data Firehose is not a streaming storage layer like Kinesis Data Streams.
Kinesis Data Firehose use producers to load data into streams in batches, after which the data is transferred to a data store. There is no need to create consumer applications or write proprietary code to process data from the Data Firehose stream. Unlike Kinesis Data Streams, Amazon Kinesis Data Firehose buffers incoming streaming data before delivering it to its destination. We chose the buffer size and buffer interval when creating a delivery stream.
Data buffers are placed within the stream and will be removed when the buffer is full or the buffer period ends. As a result, we consider Kinesis Data Firehose to be a near-real-time streaming solution.
Another distinction between Kinesis Data Streams and Kinesis Data Firehose is that Kinesis Data Firehose scales automatically.

Firehose charges depend on the quantity of data put into a delivery stream, the amount of data converted by Data Firehose, and the amount of data provided, as well as an hourly price per Availability Zone, if we send data to a VPC.
D. Kinsesis Data Analytics
Kinesis Data Analytics can read from the stream in real time , aggregate and analyse data as it moves.
It accomplishes this through the use of SQL queries or Apache Flink in Java or Scala to execute time-series analytics, feed real-time dashboards, and generate real-time metrics. We can only query data records using SQL when using Kinesis Data Firehose with Kinesis Data Analytics. Only Kinesis Data Streams support Apache Flink with Java and Scala programmes.
To organise, transform, aggregate, and analyse data at scale, Kinesis Data Analytics includes built-in templates and operators for typical processing functions. ETL, the creation of continuous metrics, and responsive real-time analytics are examples of use cases.
When specific metrics surpass predefined criteria, real-time analytics apps generate alarms or send notifications, or in more advanced scenarios, when an application discovers abnormalities using machine learning techniques.
The number of Amazon Kinesis Processing Units (KPUs) utilised to execute a streaming application affects the hourly pricing charged by Amazon Kinesis Data Analytics.
- A KPU is a stream processing capacity unit. It has one virtual CPU and four gigabytes of memory.
For more information refer,
- https://programmerprodigy.code.blog/2021/09/10/basics_event-driven_architecture/
- https://telecom.altanai.com/2013/08/02/what-is-webrtc/
- https://github.com/ravsau/aws-exam-prep/issues/10
- https://www.confluent.io/learn/batch-vs-real-time-data-processing/
- https://aws.amazon.com/solutions/case-studies/netflix-kinesis-data-streams/

{kind=link}