I took Introduction to Artificial Intelligence class at my university given by Swati Ahirao ma’am. This blog covers prerequisites for regression, common terminologies used in regression, basics of Regression, gradient descent, ways of using categorical data in regression and regularization in regression.
Things to know before learning Regression,
1.Correlation is usually defined as a measure of the linear relationship between two quantitative variables . Correlation varies between -1 to 1.

2.Co-variance indicates how two variables are related. A positive covariance means the variables are positively related, while a negative covariance means the variables are inversely related.

x = the independent variable
y = the dependent variable
n = number of data points in the sample
X ^ – = the mean of the independent variable x
Y ^ -= the mean of the dependent variable y
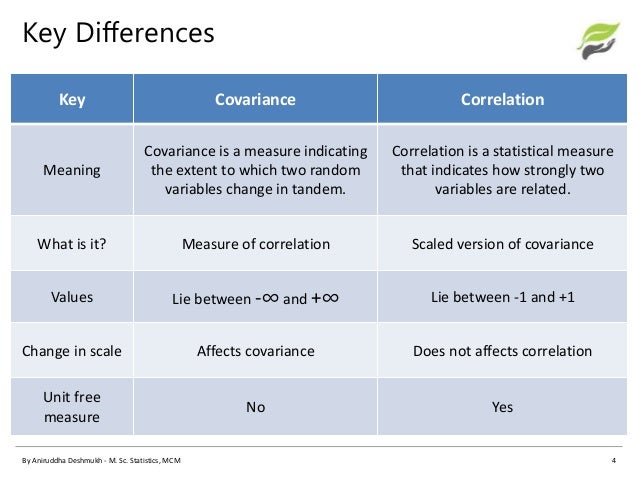
Correlation Vs Co-variance
Covariance measures variables that have different units of measurement. Using covariance, you could determine whether units were increasing or decreasing, but it was impossible to measure the degree to which the variables moved together because covariance does not use one standard unit of measurement. To measure the degree to which variables move together, you must use correlation.
To calculate the correlation coefficient for two variables, you would use the correlation formula,

r(x,y) = correlation of the variables x and y
COV(x, y) = covariance of the variables x and y
sx = sample standard deviation of the random variable x
sy = sample standard deviation of the random variable y
What do you mean by Regression?
Regression is a supervised learning technique where Y (output) is continuous/quantitative.
Common methodologies used in Regression,
1.Independent variables: A change in the independent variable directly causes a change in the dependent variable. The effect on the dependent variable is measured and recorded.
2.Dependent variable: they are “dependent” on the independent variable. When you take data in an experiment, the dependent variable is the one being measured.
3.Target variable: the variable that is or should be the output.
4.Predictor variables: the variables that are mapped to the target variable through an empirical relation ship usually determined through the data.
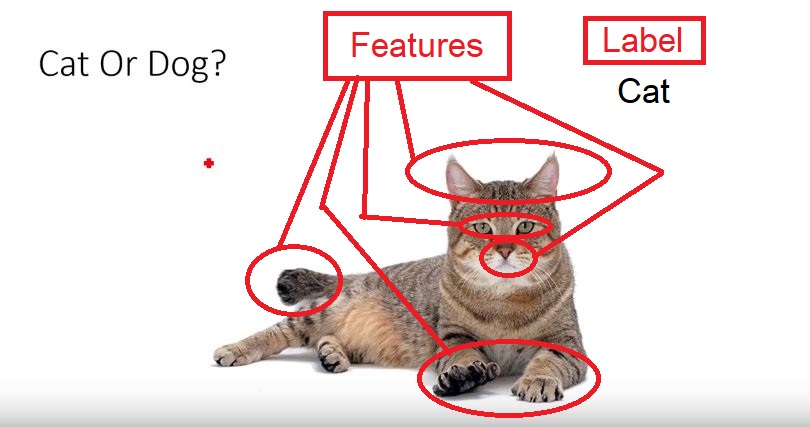
5.Features: they are individual independent variables which acts as the input in the system. Prediction models uses these features to make predictions.
New features can also be extracted from old features using a method known as ‘feature engineering’. Features are also called attributes and the number of features is dimensions
6.Label: they are the final output or target Output. It can also be considered as the output classes. We obtain labels as output when provided with features as input.
7.Epochs: An epoch elapses when an entire dateset is passed forward and backward through the model exactly one time. If the entire dataset cannot be passed into the algorithm at once, it must be divided into mini-batches.
8.The number of iterations is equivalent to the number of batches needed to complete one epoch.
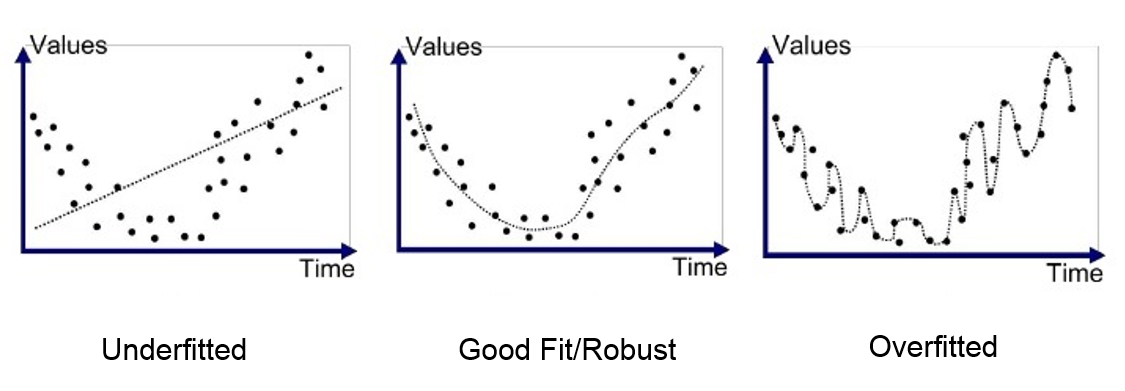
9.Under fitting: When our model can’t find the pattern in the data this maybe due to various reasons such as less data fed to the model for training.
10.Over fitting: When our model can find the pattern in our test data set and not in every data set this maybe due to too much details or features in the data set.
An example to explain under fitting and over fitting will be studying for a test,
- Under fitted students are the students who did not prepare that well for the test.
- Over fitted students are the students who basically memorized the entire study material given, but will have problems with questions outside the material given. As they did not understand the topic they simply mugged it up.
- Generalized/Robust students are the students who learned the concept from the study material and can solve similar questions outside from the study material.
11.Noise in a data set: the data points that don’t really represent the true properties of your data, but random chance.
12.Significance level: tells you how likely it is that your result has not occurred by chance.
Significance is expressed as a probability that your results have occurred by chance. You are generally looking for it to be less than a certain value.
13.Confidence level: A confidence interval (or confidence level) is a range of values that have a given probability that the true value lies within it.
Confidence intervals and significance are standard ways to show the quality of your statistical results. This will ensure that your data set and model is valid and reliable.

{kind=link}
One thought on “Introduction to Regression along with prerequisites”