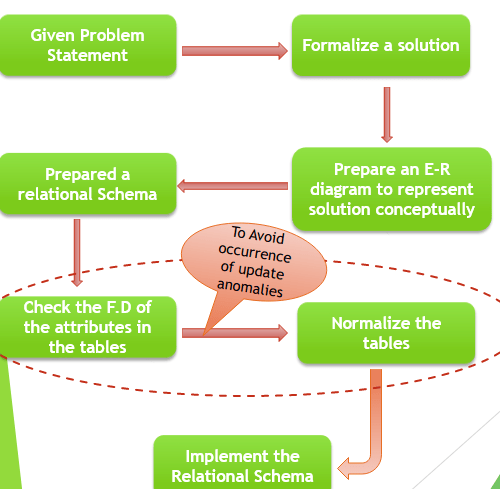
Database Development Life cycle
1.Requirement Analysis:
Requirements analysis is done in order to understand the problem, which is to be solved. There are two major activities in requirements analysis,
- Problem understanding or analysis
- Requirement specifications.
Goals of Requirements Analysis:
- To determine the data requirements of the database in terms of primitive objects.
- To classify and describe the information about these objects . .
- to identify and classify the relationships among the objects.
- To determine the types of transactions that will be executed on the database and the interactions between the data and the transactions.
- To identify rules governing the integrity of the data .
2.Database Design:
- In this phase, the information models that were developed during analysis are used to design a conceptual schema for the database and to design transaction and application.
- In conceptual schema design, the data requirements collected in Requirement Analysis phase are examined and a conceptual database schema is produced.
3.Database Design Framework:
- Determine the information requirements.
- Analyse the real-world objects that you want to model in the database.
- Determine primary key attributes.
- Develop a set of rules that govern how each table is accessed, populated and updated.
- Identify relationship between the entities.
- Plan database security.
4.DBMS Selection:
In this phase an appropriate DBMS is selected to support the information system.
A number of factors are involved in DBMS selection. They may be technical and economical factors. The technical factors are concerned with the suitability of the DBMS for information system. The following technical factors are considered.
- Type of DBMS such as relational, object-oriented etc
- Storage structure and access methods that the DBMS supports.
- User and programmer interfaces available.
- Type of query languages.
- Development tools etc.
5.Implementation :
- After the design phase and selecting a suitable DBMS, the database system is implemented.
- The purpose of this phase is to construct and install the information system according to the plan and design as described in previous phases.
- Implementation involves a series of steps leading to operational information system that includes creating database definitions, developing applications, testing the system, developing operational procedures and documentation, training the users and populating the database.
6.Design guidelines for Relational Schema:
- Meaning of the relation (Table) attributes, It should be easy to explain the meaning of entities and relationship between entities.
- Reducing repetitive values in the tuples, try to follow DRY concept
- Reducing the null values in the tuples: try to avoid, placing the attributes in a base relation whose value may usually be null.
- Not allowing the possibility of bogus tuples, When the tables are joined with equality conditions on attributes that are either primary key or foreign key.
7.Functional dependencies:
A functional dependency is an association between two attributes of the same relational database table. One of the attributes is called the determinant and the other attribute is called the determined.
If A is the determinant and B is the determined then we say that A functionally determines B and graphically represent this as A -> B.

Types of Functional Dependency:
1.Partial Dependency and Fully Functional Dependency:
1.Partial Dependency: If you have more than one attributes in primary key. Let A be the non prime key attribute. If A is not dependent upon all prime key attributes then partial dependency exists.
2.Fully functional dependency: Let A be the non-prime key attribute and value of A is dependent upon all prime key attributes. Then A is said to be fully functional dependent.

In the above example, Proj_NAME depends on Proj__NUM whereas EMP_NAME, JOB_CLASS and CHG_HOUR is depends on EMP_NUM.
A easy way to understand it would be if attribute Y is Partially dependent on the attribute X only it if it is dependent on a subset of attribute X.
2.Transitive and Non Transitive Dependency:
1.Transitive Dependency: It is due to dependency between non-prime key attributes. Suppose in a relation R, X-> Y (Y depends upon X ), Y->Z (Z depends upon Y) then X ->Z (depends upon X). There fore Z is said to be transitively dependent upon X.
2.Non Transitive dependency: There is no dependency between non-prime key attributes
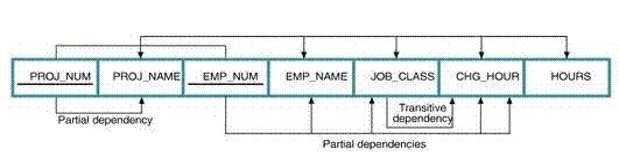
In the above example, CHG_HOUR depends on JOB_CLASS.
3. Single value and multi valued Dependency:
1.Single valued dependency: In any relation R, if for a particular value of X, Y has single value then it is know as single valued dependency.
2.Multi valued dependency(MVD): In any relation R, if or a particular value of X, Y has more than one value then it is know as multi valued dependency.
Denoted by x ->-> Y

Anomalies:
Database anomalies are the problems in relations that occur due to redundancy in the relations. These anomalies affect the process of inserting, deleting and modifying data in the relations. Some important data may be lost if a relation is updated that contains database anomalies.
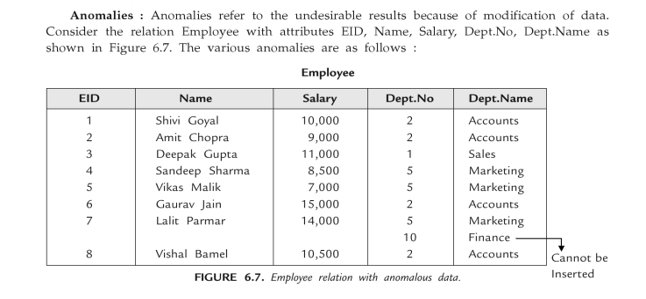
Relations that have redundant data may have problems called update anomalies, which are classified as ,
1.Insertion Anomaly:
If you want to add new information in any relation but cannot enter that data because of some constraints. In Employee, you can’t add new department Finance unless there is an employee in Finance department.
In addition to this information, it violates Entity integrity Rule 1.
2.Deletion Anomaly:
The deletion Anomaly occurs when you try to delete any existing information from any relation and this causes deletion of any other undesirable information.
In relation Employee, if you try to delete tupe containing Deepak this leads to the deletion of the department “Sales” completely.
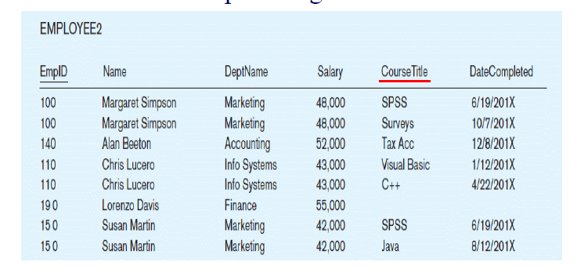
3.Update Anomaly:
The update anomaly occurs when you try to update any existing information in any relation and this causes inconsistency of data.
For Example,

Decomposition:
To Avoid anomalies and preserve the dependencies in the database.
1.Lossless Decompostion:
An example of this will be rather than storing all information in a single table, store it in multiple tables.

After Breaking a single big table into smaller tables,
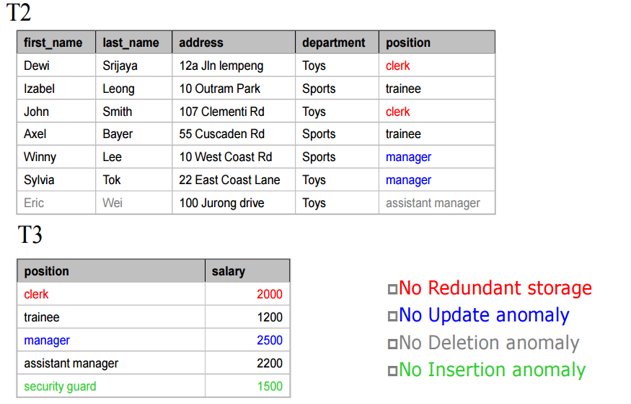
2.Dependency preserving :
If the original table is decomposed into multiple fragments, then somehow, we suppose to get all original FDs from these fragments. Every dependency in original table must be preserved or say, every dependency must be satisfied by at least one decomposed table.

Database normalization:
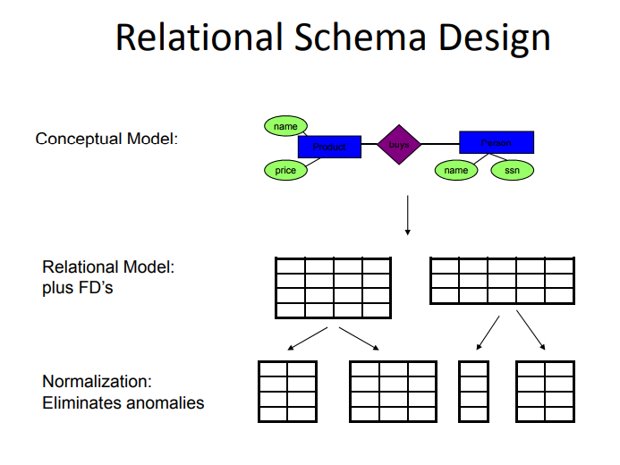
Database designed based on ER model may have some amount of inconsistency, ambiguity and redundancy. To resolve these issues some amount of refinement is required. This refinement process is called as Normalization. It has three goals:
- To eliminate redundant data (e.g. storing the same data in more than one table) a
- To store only related data in a same table.
- Organize data efficiently
- Both goals reduce the amount of space a database consumes, ensures data is logically stored, and maximize operational efficiency.
- A good database design includes the normalization, without normalization a database system may slow, inefficient and might not produce the expected result.
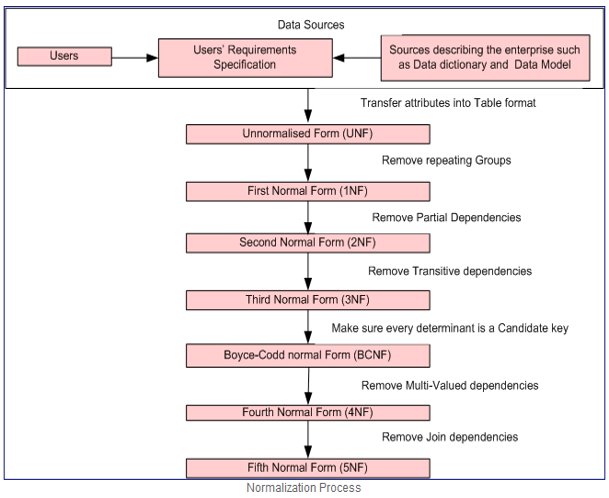
UNF to 1 NF:
First Normal Form is a relation in which the intersection of each row and column contains one and only one value.
There are two approaches to removing repeating groups from un-normalized tables:
- Removes the repeating groups by entering appropriate data in the empty columns of rows containing the repeating data.
- Removes the repeating group by placing the repeating data, along with a copy of the original key attribute(s), in a separate relation. A primary key is identified for the new relation.
The official qualifications for 1 NF are
- Each attribute name must be unique
- Each attribute values must be single
- Each row must be unique
- There is no repeating groups
For example,
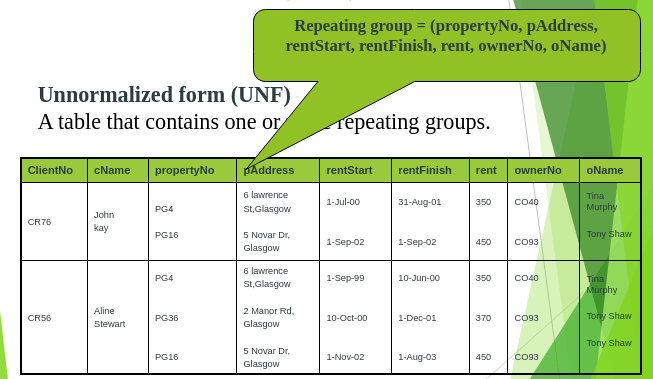
1 NF relation with the first approach
Following the concept of atomic values
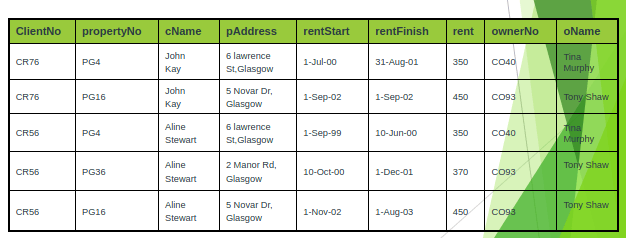
1 NF with the second approach
With the second approach, we remove the repeating group (property rented details) by placing the repeating data along with a copy of the original key attribute (clientNo) in a separte relation.
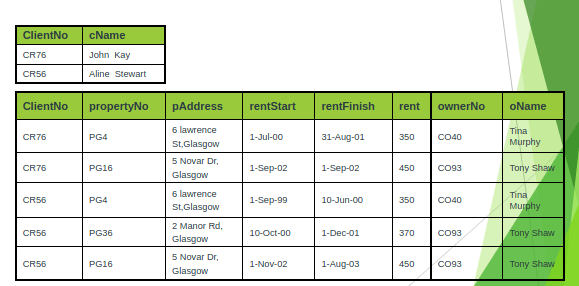
1 NF to 2 NF:
Second normal form (2NF) is a relation that is in first normal form and every non-primary-key attribute is fully functionally dependent on the primary key.
After removing the partial dependencies, the creation of the three new relations called Client, Rental, and PropertyOwner
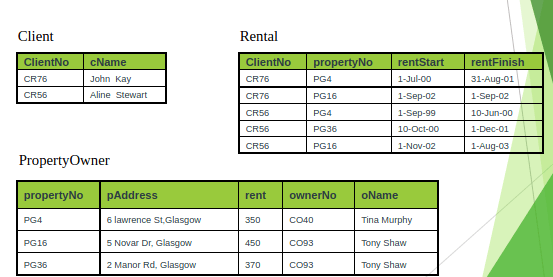
2 NF to 3 NF:
A relation that is in first and second normal form, and in which no non-primary-key attribute is transitively dependent on the primary key.
The normalization of 2NF relations to 3NF involves the removal of transitive dependencies by placing the attribute(s) in a new relation along with a copy of the determinant.

3 NF to Boyle Codd Normal Form:
A relation is said to be in BCNF when:
- If every determinant is a condidate key
- It should be in 3 NF
A relation is in BCNF, if and only if, every determinant is a candidate key.
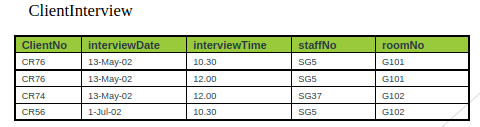
To transform the ClientInterview relation to BCNF, we must remove the violating functional dependency by creating two new relations called Interview and SatffRoom as shown below,
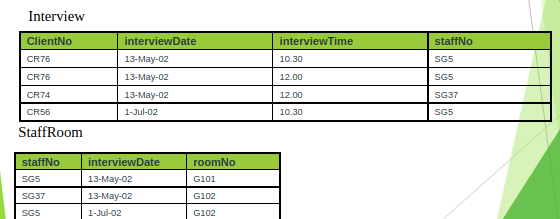
3 NF to 4 NF
A relation is said to be in 4 NF when:
- It is in BCNF
- There is no multivalued dependency in the relation. MVD occurs when two or more independent multi valued attributes are about the same attributes occur with same table.AS R->->B
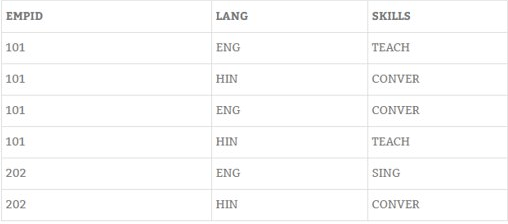
After applying 4 NF form,
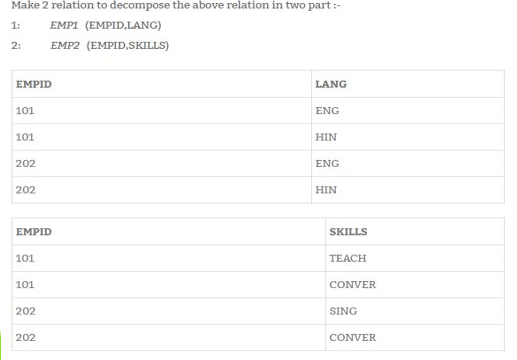
A summary would be

I worked on a Parcel Delivery System for my Junior year data base project, you can find it on GitHub.
I will be trying to write more on database in cloud, for more information about it.
- https://aws.amazon.com/products/databases/
- Amazon DynamoDB is very easy to understand and use.

One thought on “Intro into Database Management”