Data Models:
It is a collection of tools for describing data, data relationships, data semantics and data constraints.
1.Entity- Relationship model:
An entity-relationship diagram (ERD) is a data modeling technique that graphically illustrates an information system’s entities and the relationships between those entities. An ERD is a conceptual and representational model of data used to represent the entity framework infrastructure.
In simple terms , E-R model is a conceptual level model. Entity-Relationship model is based on the notion of real world entities and relationship among them. ER Model is based on:
- Entities and their attributes
- Relationships among entities

1. Entity: An entity can be a person, place, object, event or concept in the user environment about which the organization wishes to maintain data.
Real-world object distinguishable from other objects.
2.Entity sets: A collection of similar entities.
- All entities in an entity set have the same set of attributes
- Each entity set has a key
- Each attribute has a domain
3.Weak entity: A weak entity is an entity that depends on the existence of another entity. In more technical terms it can defined as an entity that cannot be identified by its own attributes. It uses a foreign key combined with its attributed to form the primary key.
The order item will be meaningless without an order so it depends on the existence of order.

Difference between strong and weak entity.

4.Attributes:
A named property or characteristic of an entity that is of interest to an organization, Different Attribute Types,
- Composite Vs. Simple Attributes: an example for composite would be Name= First name + last name. Where as in simple one, name would be equal to first name.
- Single-valued Vs. Multi-valued Attributes: an example for this would be an email id, if it is single valued then it can only store one email id per key, where as in multi valued it could store N number of email id per key,
- Derived attributes: an example for this would be storing date of birth, and calculating age from it.
- Key attributes :Covered below.

5.Relationships:
A relationship describes how entities interact. Degree of a relationship is the number of entity types that participate in it, Types of degree’s of a relationship,
- Unary Relationship: One entity related to another of the same entity type
- Binary Relationship: Entities of two different types related to each other
- Ternary Relationship: Entities of three different types related to each other

1.Cardinalities of Relationships
I try to use a verb to connect two entities. For example,
- A student can attend many classes, one class can be attended by many students.
- A driver can own many cars, but a car cannot be owned by many drivers.
Types of relationships,
- One to One relationship: one element in set A to one element in set B
- One to Many relationship: one element in set A to many elements in set B
- Many to One relationship: many elements in set A to one element in set B
- Many to many relationship: many elements in set A to many elements in set B

2.Cardinality constraints
I try to use a use case to form a constraint between two entities. For example,
- A student must attend at least one class, one class can be attended by many students.
- A driver can own at a least car, but a car cannot be owned by many drivers.
Types of cardinality constraints,
- Mandatory one: At least one element
- Mandatory many: At least more than one
- Optional one: one or zero
- Optional many: zero or more than one

6.Identifier (Key):
A key is an attribute or a combination of attributes that is used to identify records.
Sometimes we might have to retrieve data from more than one table, in those cases we require to join tables with the help of keys. The purpose of the key is to bind data together across tables without repeating all of the data in every table.
1.Super Key: An attribute or a combination of attribute that is used to identify the records uniquely is known as Super Key. A table can have many Super Keys.
2.Candidate key: An attribute or a combination of attribute that identifies the record uniquely but none of its proper subsets can identify the records uniquely.
In order to be eligible for a candidate key it must pass certain criteria:
- It must contain unique values
- It must not contain null values
- It contains the minimum number of fields to ensure uniqueness
- It must uniquely identify each record in the table
3.Primary key: A Candidate Key that is used by the database designer for unique identification of each row in a table is known as Primary Key. A Primary Key can consist of one or more attributes of a table.
As with any candidate key the primary key must contain unique values, must never be null and uniquely identify each record in the table.
4. Foreign Key: A foreign key is an attribute or combination of attribute in one base table that points to the candidate key (generally it is the primary key) of another table.
The purpose of the foreign key is to ensure referential integrity of the data i.e. only values that are supposed to appear in the database are permitted.
5.Composite Key: If we use multiple attributes to create a Primary Key then that Primary Key is called Composite Key (also called a Compound Key or Concatenated Key).
6.Alternate Key: Alternate Key can be any of the Candidate Keys except for the Primary Key.
7.Secondary Key: The attributes that are not even the Super Key but can be still used for identification of records (not unique) are known as Secondary Key.

7.Integrity Constraints
Integrity constraints are a set of rules. It is used to maintain the quality of information.
Integrity constraints ensure that the data insertion, updating, and other processes have to be performed in such a way that data integrity is not affected. Thus, integrity constraint is used to guard against accidental damage to the database.
1.Entity Constraint:
- The entity integrity constraint states that primary key value can’t be null.
- This is because the primary key value is used to identify individual rows in relation and if the primary key has a null value, then we can’t identify those rows.
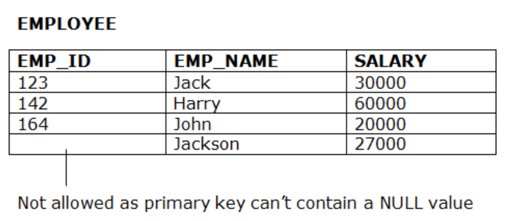
2.Domain Constraint:
- Domain constraints can be defined as the definition of a valid set of values for an attribute.
- The data type of domain includes string, character, integer, time, date, currency, etc. The value of the attribute must be available in the corresponding domain.

3.Check Constraint: A check constraint allows to state a minimum requirement for the value in a column.

4.Unique Constraint: The UNIQUE constraint ensures that all values in a column are different. Both the UNIQUE and PRIMARY KEY constraints provide a guarantee for uniqueness for a column or set of columns.
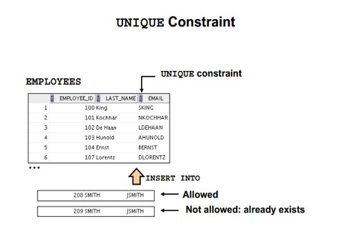
5.Referential Integrity:
- A referential integrity constraint is specified between two tables.
- In the Referential integrity constraints, if a foreign key in Table 1 refers to the Primary Key of Table 2, then every value of the Foreign Key in Table 1 must be null or be available in Table 2.

8.Key Constraints
1.Primary Key Constraint: Primary key is to uniquely identify each record in a table. It must have unique values and cannot contain nulls. Thus PRIMARY KEY = NOT NULL+ UNIQUE.
2.Foreign Key Constraint: Foreign keys are the fields of a table that point to the primary key of another table. They act as a cross-reference between tables. It has two types:
- Cascade Update
- Cascade Delete

3.Default Constraint: The DEFAULT constraint is used to provide a default value for a column. The default value will be added to all new records IF no other value is specified.

2.Relational Model:
In this model ,data is organized in two dimensional tables called relations. Relational Model is made up of tables,
- A row of table = a relational instance/tuple
- A column of table = an attribute
- A table = a schema/relation
- Cardinality = number of rows
- Degree = number of columns

3.Conversion Rules to relational model
STEP 1: For each non-weak entity, create a relation (or table) that includes all of the simple attributes of that entity.
- Do not include multi valued attributes or derived attributes at this time. If you have a composite attribute, include only the component attributes.
- Choose one of the candidate keys to be the primary key of the table.
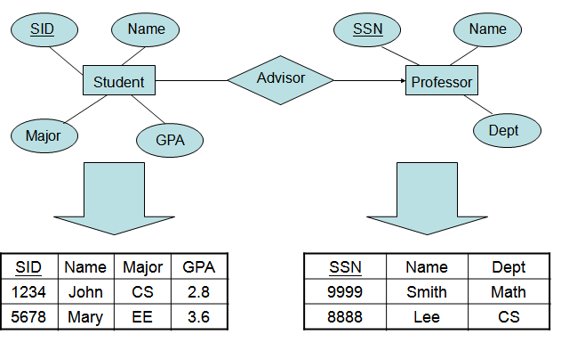
STEP 2: For each weak entity, create a relation that includes all simple attributes of the weak entity.
- In addition, include as a foreign key attribute the primary key of the owning entity.
- The primary key of this relation will be the combination of the primary key of the owning entity and the partial key of the weak entity.

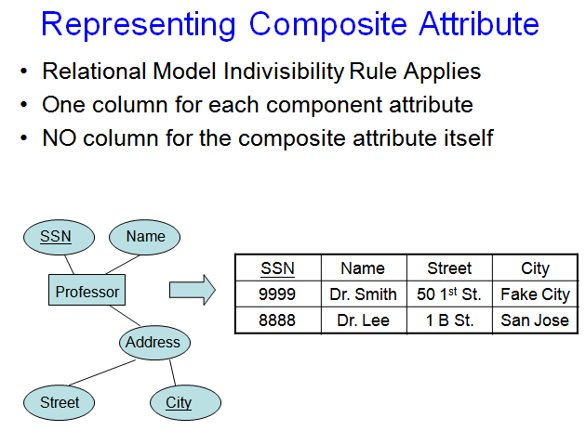
Step 3: For each multi valued attribute, create a new relation that includes that attribute, plus the primary key of the entity to whom that attribute belongs as a foreign key. The primary key of this new relation will be the combination of the foreign key and the attribute itself.
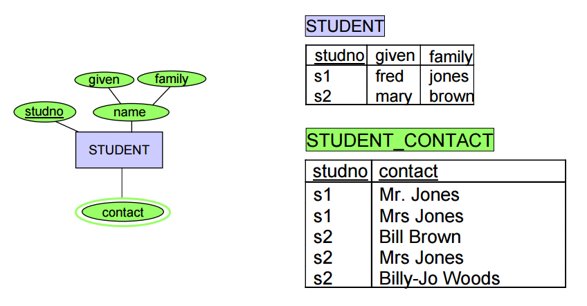
Step 4: Convert relationships into relational model,
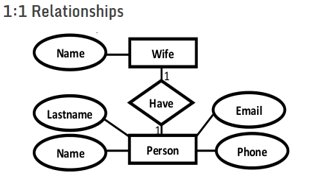
1.Relationship Conversion: 1:1
For each binary 1:1 relationship, identify the two entities that participate in that relationship. Take the primary key from table and include it as a foreign key in the other table

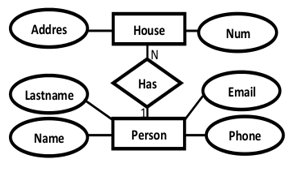
2.Relationship Conversion: 1:N
For each 1:N relationship, the primary key of “1” side is added as a foreign key in the table on “N” side entity.

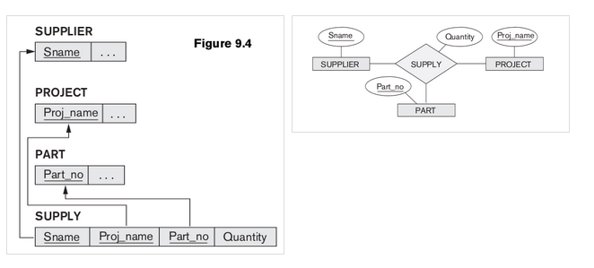
3.Relationship Conversion: M:N
For each binary M:N relationship, create a new relation to represent the relationship. Include in this relation as foreign keys the primary keys of each of the entities that participates in the relationship. The combination of these foreign keys will make up the primary key for the new table.

4.Conversion of N-ary relationship
For each n-ary relationship create a relation to represent it. Add a foreign key into each participating entity type. Also add any attributes of the relationship. The primary key of this relation is the combination of all foreign keys into participating entity
Step 5: Checking for sub classes and super classes
- Super-class: An entity type that includes one or more dissimilar sub-groupings of its occurrences that is required to be represented in a data model.
- Sub-class: A distinct sub-grouping of occurrences of an entity type that require being represented in a data model.
1. Generalization:
Generalization is the process of extracting common properties from a set of entities and creating a generalized entity from it. It is a bottom-up approach in which two or more entities can be generalized to a higher level entity if they have some attributes in common.
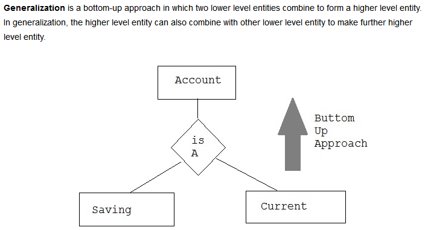
2.Specialization:
In specialization, an entity is divided into sub-entities based on their characteristics. It is a top-down approach where a higher level entity is specialized into two or more lower level entities.

3.Aggregation:
Sometimes you may want to model a ‘has-a,’ ‘is-a’ or ‘is-part-of’ relationship, in which one entity represents a larger entity (the ‘whole’) that will consist of smaller entities (the ‘parts’). This special kind of relationship is termed as an aggregation. Aggregation does not change the meaning of navigation and routing across the relationship between the whole and its parts.

Q. How to confirm a database is Relational?
Codd’s rules proposed by E. F. Codd, designed to define what is required from a database management system in order for it to be considered relational .
For a system to qualify as a relational database management system (RDBMS), that system must use its relational facilities to manage the database.
For more information on codd’s twelve rules, refer this article by Joe Celko.

One thought on “Intro into Database Management”