As data becomes more diverse and valuable, we put more emphasis on data-driven architecture. Developers need to understand the importance of accuracy, consistency, and quality of data. So they can develop quality data pipelines and products on the cloud while focusing on data.
This blog explains what data is, how can we enrich our data, how can we analyse our data, and how to best use our data. We will be covering AWS Glue, AWS QuickSight, and AWS Sagemaker.
Inspiration for this blog was after reading the Forbes Blog on “The Age Of Analytics And The Importance Of Data Quality”.
- https://www.forbes.com/sites/forbesagencycouncil/2019/10/01/the-age-of-analytics-and-the-importance-of-data-quality/?sh=76cca4fa5c3c
- https://www.freecodecamp.org/news/is-data-important-to-your-business/
Q.What is Data?
Data is raw information. For example, your daily consumption of coffee. It is raw information about the amount of coffee you have consumed, but if you analyse it and gain insights from it.
- Types of coffee beans or coffee flavour
- How much sugar do you put into the coffee?

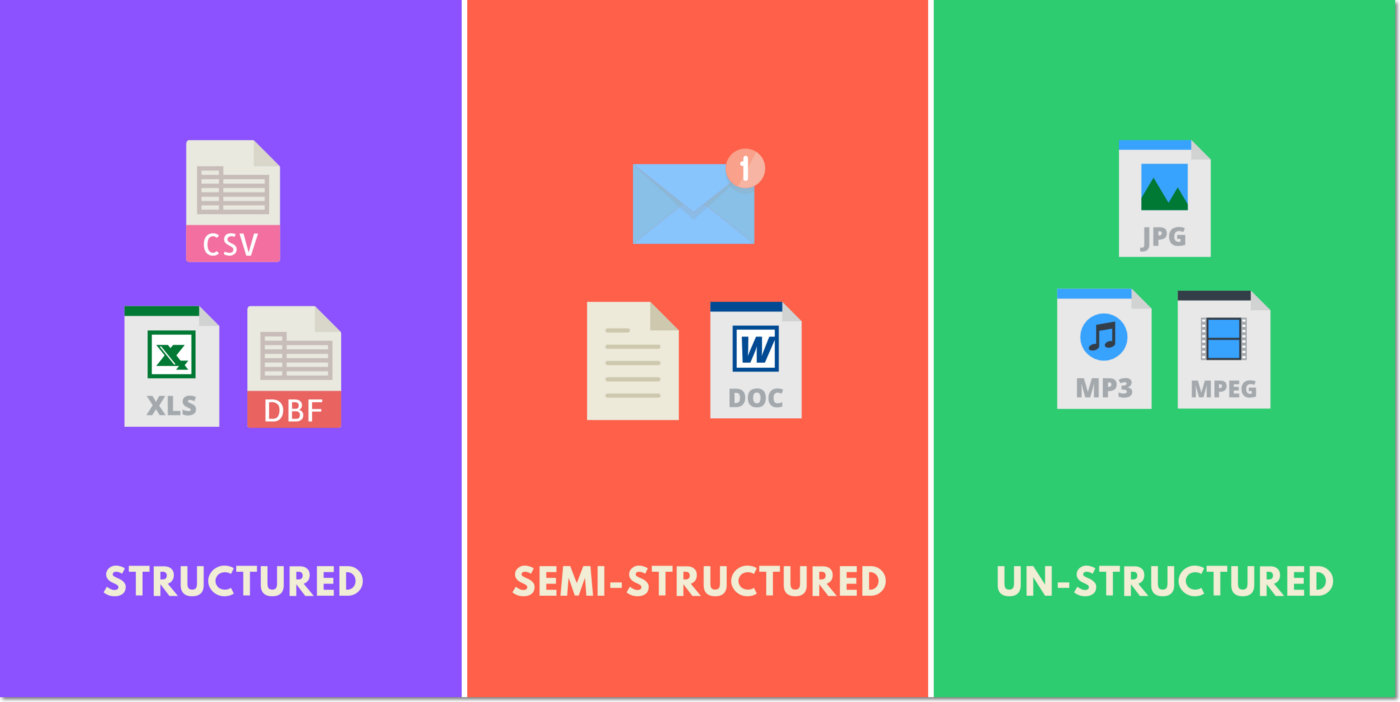
Now that we differentiate between information and data. There are many formats to store and transfer data, these formats depend on the type of data. For example,
- Write coffee ingredients on a piece of paper i.e unstructured
- Write it in a .csv file i.e structured
- A combination of both i.e semi-structured.
Q.How to enrich our data?
As a data engineer, you would like to maximise the insights you could gather from your data. Some data formats are developer-friendly, and some are not. So we need to convert data to developer-friendly formats, there are many ways of doing it.
An example of no/low code could be AWS Glue,
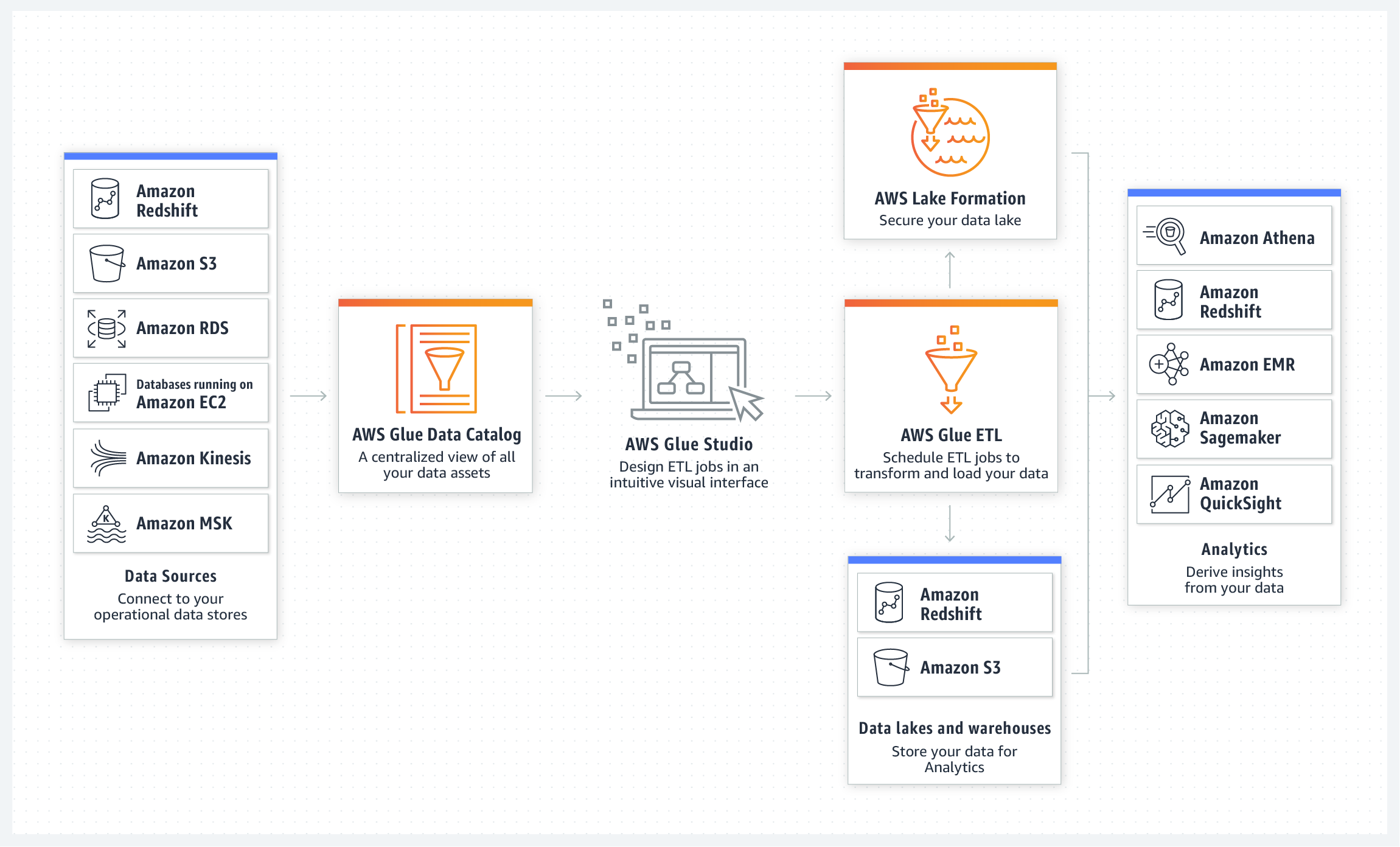
AWS Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorise your data, clean it, enrich it, and move it reliably between various data stores and data streams.
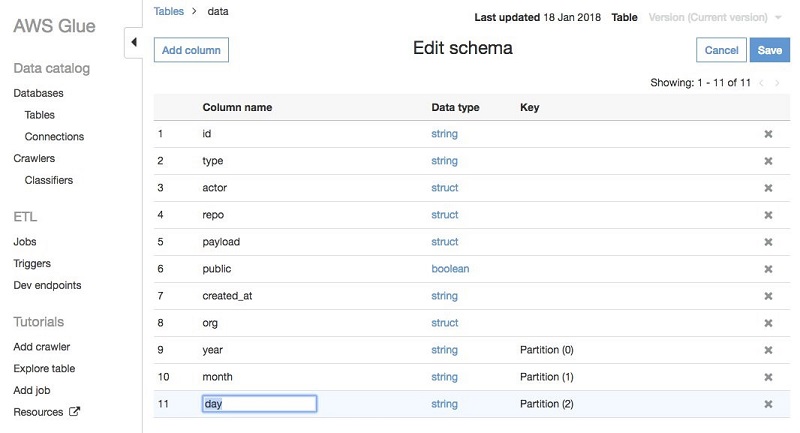
You can store your data using various AWS services and still maintain a unified view of your data using the AWS Glue Data Catalogue. Use Data Catalogue to search and discover the datasets that you own, and maintain the relevant metadata in one central repository.
Q.How does AWS Glue work?
You define jobs in AWS Glue to do the work that’s required to extract, transform, and load (ETL) data from a data source to a data target. You perform the following actions:
- For datastore sources, you define a crawler to populate your AWS Glue Data Catalogue with metadata table definitions.
- Point your crawler at a data store, and the crawler creates table definitions in the Data Catalogue.
- AWS Glue can generate a script to transform your data or, you can provide the script in the AWS Glue console or API.( currently in Python and Scala scripts)
- You can run your job on-demand, or you can set it up to start when a specified trigger occurs. The trigger can be a time-based schedule or an event.
You use the AWS Glue console to define and orchestrate your ETL workflow. The console calls several API operations in the AWS Glue Data Catalogue and AWS Glue Jobs system to perform the following tasks:
- Define AWS Glue objects such as jobs, tables, crawlers, and connections.
- Schedule when crawlers run.
- Define events or schedules for job triggers.
- Search and filter lists of AWS Glue objects.
- Edit transformation scripts.
If you don’t prefer a No/Low code solution, you should try Pandas Library. Pandas library is great for data wrangling, and most of the data engineers will have experience with Pandas.
For more information, feel free to listen to my session on introduction to AWS Glue where I compare No/Low code solutions to Pandas library:
Q.What to do after enriching your data?
Data visualisation helps you to visualise your data as maps or graphs and interact with them. This makes it much easier for the human mind to digest the data and thus allowing it to spot patterns and trends in a much better way. This could be either done by standard business analysis tools like Tableau or R or python. A few key benefits are,
- Identifying important trends depending on the type of visualisation can help you to determine trends over time amongst a data set.
- Being able to spot and identify relationships within your data is key, it can help you to both drive future business decisions in the right direction and also to make corrective actions elsewhere.
- Having a quick reference to a visualisation allows the data to collaborate with many recipients.

There are a variety of ways to present your data, depending on what type of data you are trying to show. For each use case, there will be a specific type of chart, for example:
- To present data that shows relationships between data points, use scatter or bubble chart.
- To compare data between two or more data sets, use either a Bar, Column or Line chart.
- Looking at the distribution of data across an entire data set, use a histogram.
- Represent the part-to-whole relationship of a data set, use a pie chart, stacked column chart, 100% stacked column chart, or a treemap.

An example of no/low code could be AWS QuickSight
Amazon QuickSight allows everyone to understand your data by asking questions in natural language, exploring through interactive dashboards, or looking for patterns and outliers powered by machine learning.
Quicksight allows you to share dashboards, email reports, and embedded analytics. By taking your data and visually displaying the questions you want to answer you can gain relevant insights into your company data
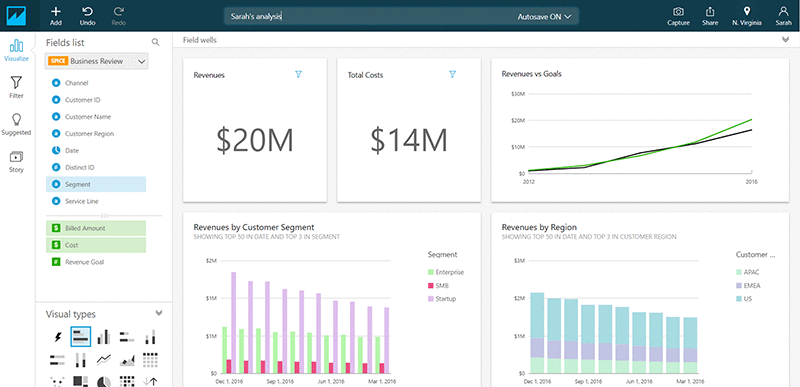
It allows you to draw various graphs and charts using options in User Interface. There are a lot of different options to work with. Let’s cover a few terminologies
- Fields: These reflect the columns of the table in the database.
- Visual Types: This is how your data will be represented. This can be from a simple sum to a chart/graph or even a heat map.
- Sheets: These allow for many visuals to be stored together on a single page. To keep things simple, we’ll be working with only one sheet.
Try changing the Visual Type of this data and see how it’s represented. You might need to add extra fields to the Field wells to make them populate correctly.
QuickSight, by default, has an automatic save feature enabled by default for each analysis. Personally, the case study of Quicksight in the NFL has to be one of the interesting use cases reads.
If you don’t prefer a No/Low code solution, you should try looking into MatplotLib, Seaborn, and Bokeh Library. They are great for data visualisation and most of the data engineers will have experience with them.
Q.How can we predict an outcome using our data?
After Data visualisation helps us understand patterns in data. We would like to predict/classify an outcome based on historical data.
Q.What is Machine learning?
Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.

An example of low code Machine learning solutions. When considering Machine learning solutions, there are many use cases to consider. Let us consider a few,
- Extract text and data from documents: Rather than building up your Model from scratch, you could use AWS Textract.
- Amazon Textract extracts text, handwriting, and data from scanned documents.
- If you want to build Chatbots, then AWS Lex would help you build chatbots.
- To design, build, test, and deploy conversational interfaces in applications using advanced natural language models.
- If you want to automate speech recognition, AWS Transcribe.
- An automatic speech recognition service that makes it easy to add speech to text capabilities to any application. Consider the use case of Alexa.
For more information on various machine learning general use case solutions refer to,
If you don’t prefer Low code solution, you should try looking into Sagemaker. They are good for computing and deploying your ML models, as you get AWS compute servers.
Q.What is a sagemaker?
At its core, sagemaker is a fully managed service that provides the tools to build, train and deploy machine learning models. It has some components in it such as managing notebooks and helping label and train models deploy models with a variety of ways to use endpoints.
SageMaker algorithms are available via container images. Each region that supports SageMaker has its copy of the images. You will begin by retrieving the URI of the container image for the current session’s region. You can also utilise your own container images for specific ML algorithms.
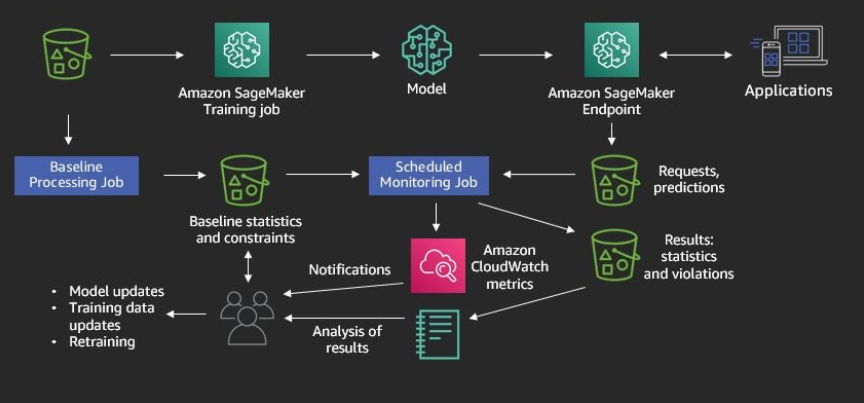
Q.How can we host Sagemaker models?
SageMaker can host models through its hosting services. The model is accessible to the client through a SageMaker endpoint. The Endpoint is accessible over HTTPS and SageMaker Python SDK.
Another way would be using AWS Batch. It manages the processing of large datasets within the limits of specified parameters. When a batch transform job starts, SageMaker initialises compute instances and distributes the inference or pre-processing workload between them.
In Batch Transform, you provide your inference data as an S3 URI and SageMaker will care of downloading it, running the prediction and uploading the results afterwards to S3 again.
Batch Transform partitions the Amazon S3 objects in the input by key and maps Amazon S3 objects to an instance. To split input files into mini-batches you create a batch transform job, set the SplitType parameter value to Line. You can control the size of the mini-batches by using the BatchStrategy and MaxPayloadInMB parameters.
After processing, it creates an output file with the same name and the .out file extension. The batch transforms job stores the output files in the specified location in Amazon S3, such as s3://awsexamplebucket/output/.
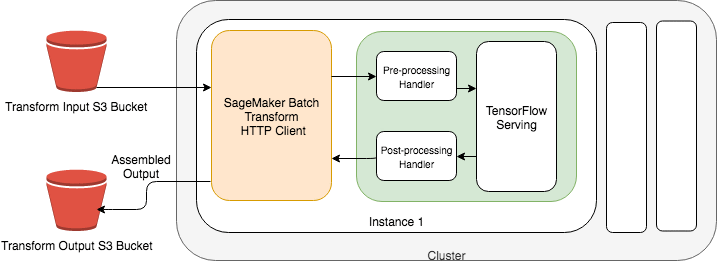
The predictions in an output file are in the same order as the corresponding records in the input file. To combine the results of many output files into a single output file, set the AssembleWith parameter to Line.
For more information refer,
- https://docs.aws.amazon.com/sagemaker/latest/dg/batch-transform.html
- https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-batch.html
- https://docs.aws.amazon.com/sagemaker/latest/dg/ex1-model-deployment.html#ex1-batch-transform
Q. How to Select the right to compute instance?
Choosing a Compute instance completely biased on either price or compute, might not be a good option. As you select a cheaper compute instance, it takes you about 30 mins. But if you would have selected a better compute instance, it takes 10 mins. The second alternative would have been a better alternative economically and time-based.
Some points to remember while choosing CPU and GPU will be
- The CPU time grows proportional to the size of the matrix squared or cubed.
- The GPU time grows almost linearly with the size of the matrix for the sizes used in the experiment. It can add more compute cores to complete the computation in much shorter times than a CPU.
- Sometimes the CPU performs better than GPU for these small sizes. In general, GPU excel for large-scale problems.
- For larger problems, GPUs can offer speedups in the hundreds. For Example, an application used for facial or object detection in an image or a video will need more computing. Hence GPUs might be a better solution.
For more information, feel free to listen to my session on introduction to Algorithms and AWS Sagemaker:
For more information on Sagemaker,
After considering all the no/low code solutions and coding solutions. Let’s consider a use case,
If you have a relatively small business with not that much need of customisation, then perhaps no/low code solutions. But if you want to customise your application, you would have to you coding solutions. A point to remember, depending on your datasets size, diversity and quality, you could either go for CPU(less compute) or GPU (more compute).
