I spent over a couple of weeks reading about cloud storage, types of cloud storage, Block Storage( AWS EBS), Object Storage(AWS S3), different types of Objects Storage options, File Storage( AWS EFS) and disaster recovery using cloud storage. I have started with explaining what do you mean by cloud storage and how does it work.
What do you mean by Cloud Storage ?
Cloud storage stores data on the Internet through a cloud computing provider who manages and operates data storage as a service. It’s delivered on demand with just-in-time capacity and costs, and eliminates buying and managing your own data storage infrastructure.
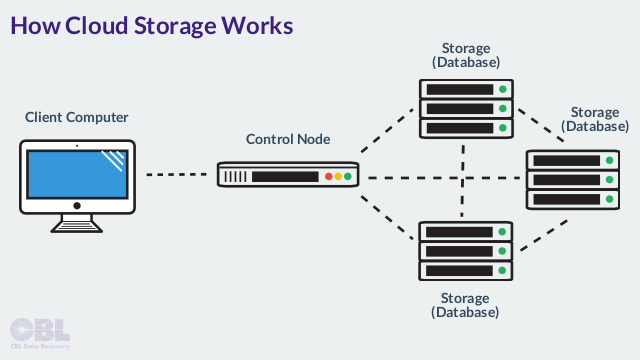
How Does Cloud Storage Work?
Cloud storage is purchased from a third party cloud vendor who owns and operates data storage capacity and delivers it over the Internet in a pay-as-you-go model.
Applications access cloud storage through traditional storage protocols or directly via an API.
Benefits of Cloud Storage,
- Cost of Ownership: With cloud storage, there is no hardware to purchase, storage to provision. You can add or remove capacity on demand, quickly change performance and retention characteristics, and only pay for storage that you actually use.
- Time for Deployment: Cloud storage allows IT to quickly deliver the exact amount of storage needed, right when it’s needed.
Types of Cloud Storage
There are three types of cloud data storage: object storage, file storage, and block storage. Each offers their own advantages and have their own use cases,

A. Block Storage: It breaks up data into blocks and then stores those blocks as separate pieces, each with a unique identifier.
- Block storage also decouples data from user environments, allowing that data to be spread across multiple environments.
- They are provisioned with each virtual server and offer the ultra low latency required for high performance workloads.
- Developers favor block storage for computing situations where they require fast, efficient, and reliable data transportation.
Amazon Elastic Block Store (Amazon EBS) provides block level storage volumes for use with EC2 instances. EBS volumes that are attached to an instance are exposed as storage volumes that persist independently from the life of the instance.
- Only a single EBS volume can be attached to a single EC2 instance, however multiple EBS volumes can be attached to a single instance.
- Every write to an EBS volume is replicated multiple times within the same availability zone of your region. This means that the EBS volume is only available in a single availability zone.
- Majorly Used for fast Input/Output Operations per second(IOPS).
- Provides an option to perform back-ups of data know as snapshots, they are incremental.
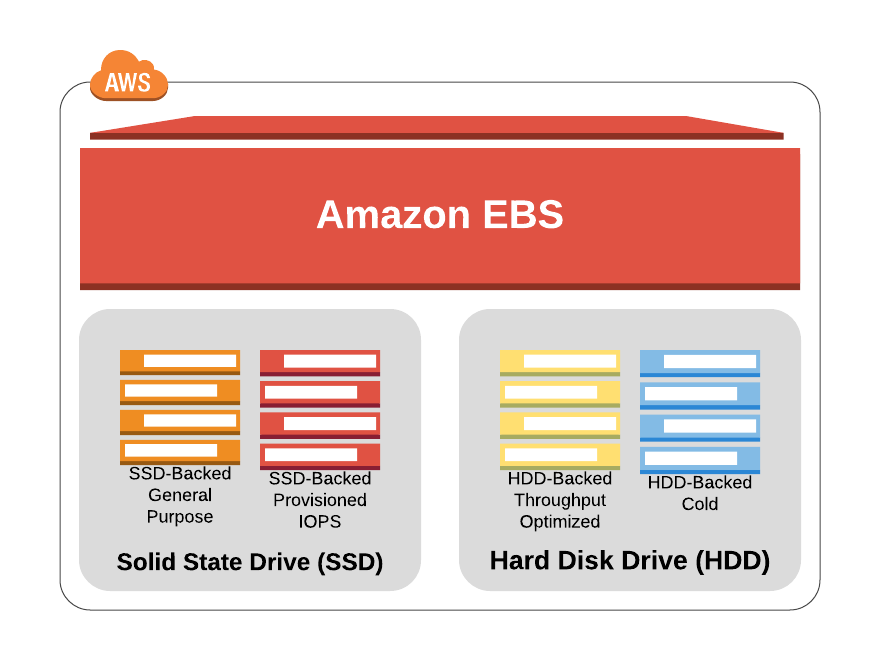
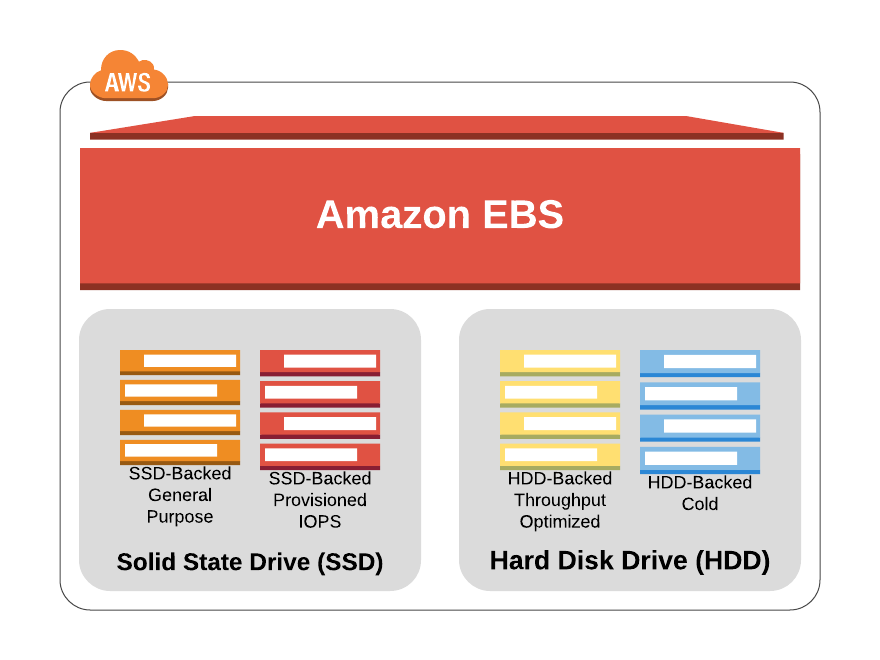
Different EBS Volume types,
- Solid state drive (SSD):
- Suited for work with smaller blocks as boot volumes for EC2 instances
- Hard disk drives (HDDs)
- Suited for workloads that require higher throughput/large blocks of data.
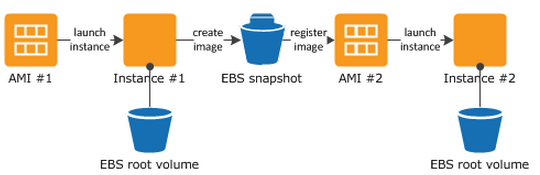
How to create an EBS Volume?
- During the creation of a new instance and attach it at the time of the launch
- From within the EC2 dashboard of the AWS management console as a standalone volume ready to be attached to an instance when required.
Do not use EBS for temporary storage or multi instance storage access as they can be accessed by one instance at a time.
For more information on on Block Storage,
- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AmazonEBS.html
- https://aws.amazon.com/ebs/?ebs-whats-new.sort-by=item.additionalFields.postDateTime&ebs-whats-new.sort-order=desc
- https://in.pcmag.com/storage/42372/ssd-vs-hdd-whats-the-difference
B.Object Storage: Data that does not conform to, or cannot be organized easily into, a traditional relational database with rows and columns.
They are ideal for building modern applications from scratch that require scale and flexibility, and can also be used to import existing data stores for analytics, backup, or archive.
AWS Simple Storage Service(S3) is a fully managed, object-based storage service that is highly available, highly durable, very cost-effective, and widely accessible.
S3 is a regional service and so when uploading data you as the customer are required to specify the regional location for that data to be placed in.

How to store objects in S3,
- Define and create a bucket( bucket = container for your data.).
- This bucket name must be completely unique, not just within the region you specify, but globally against all other S3 buckets that exist, because of the flat address space, you simply can’t have a duplicate name.
- Once you have created your bucket you can then begin to upload your data within it. Any object uploaded to your buckets are given a unique object key to identify it.
- Can if required create folders within the bucket to aid with categorization of your objects for easier data management

Different types of AWS Storage classes,
- S3 Standard:
- It is ideal when you need high throughput with low latency with the added ability of being able to access your data frequently.
- S3 Standard offers eleven nines of durability across multiple availability zones. It offers a 99.99% availability SLA.
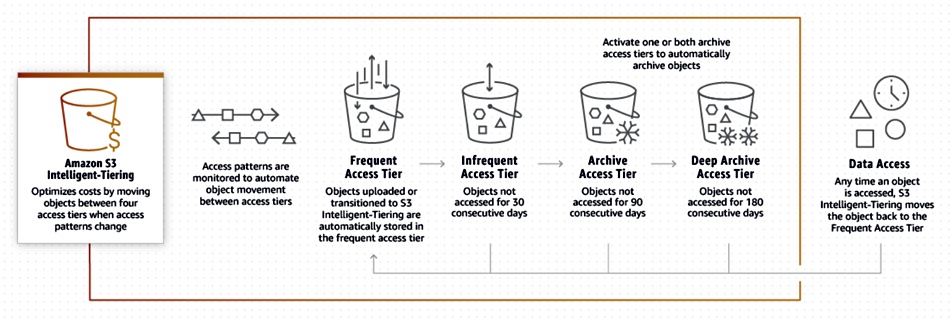
- S3 Intelligent Tiering:
- Ideal when the frequency of access to the object is unknown. Depending on your data access patterns of objects in the Intelligent Tiering Class, S3 will move your objects between two different tiers,
- frequent access
- infrequent access
- S3 Intelligent Tiering also offers 11 nines of durability across multiple availability zones. It offers a 99.9% availability SLA.
- Ideal when the frequency of access to the object is unknown. Depending on your data access patterns of objects in the Intelligent Tiering Class, S3 will move your objects between two different tiers,
- S3 Standard infrequent access:
- It is designed for data that does not need to be accessed as frequently as data within the Standard tier, and yet still offers high throughput and low latency access, much like S3 Standard does.
- It carries that 11 nines durability across multiple AZs, by copying your objects to multiple availability zones within a single region to protect against AZ outages. It offers a 99.99% availability SLA.
- S3 One Zone Infrequent Access:
- An infrequent storage class it is designed for objects that are unlikely to be accessed frequently. It also carries the same throughput and low latency. The objects will be copied multiple times to different storage locations within the same availability zone instead of across multiple availability zones.
- One Zone IA offers the lowest level of availability which is currently 99.5 percent and this is down to the fact that your data is being stored in a single availability zone.

AWS Simple Storage Service Glacier (S3 Glacier): The fundamental difference with the Amazon Glacier storage classes come at a fraction of the cost when it comes to storing the same amount of data than the S3 storage classes. As it doesn’t provide you instant access to your data.
When retrieving your data it can take up to several hours to gain access to it depending on certain criteria. The data structure within Glacier is centered around vaults and Archives. A Glacier vault simply acts as a container for Glacier archives. These vaults are regional.
The Glacier dashboard within AWS management console allows you to create your vaults, set data retrieval policies, and event notifications. When it comes to moving data into S3 Glacier for the first time it’s effectively a two-step process,
- You need to create your vaults as your container for your archives and this could be completed using the Glacier console.
- You need to move your data into the Glacier vault using the available API or SDKs.
The default Standard storage class within S3 Glacier,
- It is highly secure using in transit and at rest encryption low-cost and durable storage solution.
- The durability matches that of other S3 storage classes, being 11 nines across multiple availability zones, and the availability of S3 Glacier is 99.9%.
- It does offer a variety of retrieval options depending on how urgently you need the data back, each offering a different price point. These being expedited, Standard, and bulk.
- Expedited: This is used when you have an urgent requirement to retrieve your data but the request has to be less than 250 megabytes.
- Standard: This can be used to retrieve any of your archives no matter their size but your data will be available in three to five hours.
- Bulk: This option is used to retrieve petabytes of data at a time, however, this typically takes between five and twelve hours to complete.

S3 Glacier Deep Archive: An ideal storage class for circumstances that require specific data retention regulations and compliance with minimal access. The durability and availability matches that of S3 Glacier with 11 nines durability across multiple AZs with 99.9% availability.
Deep Archive, however, does not offer multiple retrieval options. Instead, AWS states that the retrieval of the data will be within 12 hours or less.
It is essentially used for data archiving and long-term data retention, and is commonly referred to as the cold storage service within AWS.
For more information on Object Storage,
- https://aws.amazon.com/what-is-cloud-object-storage/
- https://aws.amazon.com/s3/
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/UsingObjects.html
C.File Storage: It is a hierarchical storage methodology used to organize and store data on a computer hard drive or on network-attached storage (NAS) device.
- In file storage, data is stored in files, the files are organized in folders, and the folders are organized under a hierarchy of directories and sub directories.
- They are ideal for use cases like large content repositories, development environments, media stores, or user home directories.
Amazon Elastic File Storage(EFS) is considered file level storage and is also optimized for low latency access, but unlike EBS it supports access by multiple EC2 instances.
- It appears to users like a file manager interface and uses standard file system semantics, such as locking files, renaming files, updating them, and using a hierarchical structure.
- EFS provides simple, scalable file storage for use with Amazon EC2 instances. EC2 instances can be configured to access Amazon EFS instances using configured mount points.
Some features of the service,
- It’s a fully managed file system for multiple EC2 instances, allowing it to serve as a common data source across potentially thousands of EC2 instances.
- It uses standard operating system APIs, so any application that is designed to work with standard operating system APIs will work with EFS.
- It’s replicated across availability zones in a region, meaning it’s highly available.
- It provides low latency and can support thousands of concurrent connections.
- The through put and IOPS scale dynamically as required.

Q.How do we use EFS?
- You create the file system, you can access it by creating mount points within your virtual private cloud, or VPC.
- Once the mount points have been created, the NFS file system target can be accessed from any other machine.
- When the file system has been mounted to one or more instances, you can read and write data to the file system. That means that users within the region have access to a common data source.
- EFS can also be used for premises-based solutions, Amazon provides an option called AWS Direct Connect.
- An EFS file system can be mounted on a premises-based server then data can be migrated to the AWS cloud, hosted on an EFS file system.

AWS Cloud Storage for Disaster Recovery
Cloud storage services can be considerably cheaper as a backup solution than that of your own on-premise solution. The speed in which you can launch an environment within AWS to replicate your on-premise solution, with easy access to production backup data, is of significant value to many organizations.
Considerations when planning an AWS DR Storage Solution,
Q1.How will you get your data in and out of AWS ?
The method on which you choose to move your data from on-premise into the cloud can vary depending on your own infrastructure and circumstances.
- You can use Direct Connect connection to AWS to move data in and out of the environment.
- If you don’t have a direct connection link between your data center and AWS then you may have a hardware or software VPN connection which could also be used.
- If you don’t have either of these as connectivity options then you can use your own internet connection from the data center to connect and transfer the data to AWS.
- The AWS Storage Gateway service is a method which acts as a gateway between your data center and your AWS environment.
Depending on how much data you need to move or copy to AWS, then these lines of connectivity may not have the required bandwidth to cope with the amount of data transferred. In this instance, there are physical disc appliances that are available,
- AWS Snowball service, whereby AWS will send you an appliance, either 50 Terrabytes or 80 Terrabytes in size, to your data center, where you can then copy your data to it before it is shipped back to AWS for uploading onto S3.
- AWS Snowmobile, this is an Exabyte-scale data transfer service, where you can transfer up to 100 Petabytes per Snowmobile, which is a 45-foot long shipping container pulled by a semi-trailer truck.
Q2.How quickly do you need your data back?
Some storage services offer immediate access to your data, such as Amazon S3, while others may require several hours to retrieve, such as Amazon Glacier Standard Retrieval.
Q3.How to Secure the data?
When working with sensitive information, you must ensure that you have a means of encryption both in-transit and when at rest.
To check how AWS storage services stack up against this governance, AWS has a service called AWS Artifact, it allows customers to view and access AWS Compliance Reports.
Some of these security features, which can help you maintain a level of data protection are:
- IAM Policies
- Bucket Policies
- Access Control Lists
- Lifecycle Policies
- Multi-Factor Authentication Delete ensures that a user has to enter a 6 digit MFA code to delete an object, which prevents accidental deletion due to human error.
- Enabling versioning on an S3 bucket, ensures you can recover from misuse of an object or accidental deletion, and revert back to an older version of the same data object.

S3 as a data backup Solution?
Amazon S3 is a highly available and durable service, with huge capacity for scaling and along with numerous security features to maintain a tightly secure environment.
This makes S3 an ideal storage solution for static content, which makes Amazon S3 perfect as a backup solution. Amazon S3 provides three different classes of storage, each designed to provide a different level of service and benefit.
- S3 Standard
- S3 Infrequent Access
- S3 Glacier
As a general rule, if your data retrieval will take longer than a week using your existing connection method, then you should consider using AWS Snowball.
You can use AWS Storage Gateway for on-premise data backup. It allows integration between your on-premise storage and that of AWS. This connectivity can allow you scale your storage requirements both securely and cost efficiently.
Storage Gateway offers different configurations and options allowing you to use the service to fit your needs. It offers file, volume and tape gateway configurations which you can use to help with your DR and data backup solutions.

For more information on Disaster Recovery,
- https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/plan-for-disaster-recovery-dr.html
- https://aws.amazon.com/blogs/database/implementing-a-disaster-recovery-strategy-with-amazon-rds/
- https://docs.aws.amazon.com/prescriptive-guidance/latest/backup-recovery/on-premises-to-aws.html
For more information, https://awseducate.instructure.com/courses/197/pages/aws-cloud-computing-fundamentals?module_item_id=9215
I will be spending next couple of weeks focusing on AWS databases. Let me know where i could improve at?



{kind=link}
{kind=link}
2 thoughts on “Introduction to Cloud Storage”